-
[PostgreSQL] limit과 offset의 성능 저하 줄이기DB/PostgreSQL 2021. 10. 30. 18:30
보통 pagination을 구현할 때, SQL의 limit과 offset을 많이 사용합니다. 테이블의 레코드 수가 크지 않다면 문제가 되진 않지만 몇십만건 이상일 경우, 성능 저하가 올 수 있습니다.
아래는 1200만건 정도의 레코드가 있는 테이블에서 limit, offset으로 특정 구간을 pagination한 쿼리입니다.
select * from orders limit 10000 offset 10000000;
offset으로 10,000,000을 주었기 때문에,1000만건을 full scan 후 limit으로 주어진 10,000건을 조회하여 보여주고 있습니다. 위의 쿼리는 정렬순서가 없어서 테이블에 저장되어 있는 순서대로 추출했지만 아래와 같이 pk나 다른 키로 정렬을 준다면 수행시간이 더 늘어나는 것을 볼 수 있습니다.
select * from orders order by orders_id limit 10000 offset 10000000;
select * from orders order by price limit 10000 offset 10000000;
pk와 같이 인덱스가 추가되어 있는 키를 정렬하는 케이스는 그나마 괜찮지만 인덱스가 추가되어 있지 않으면 full scan 후 모든 데이터들을 정렬하므로 비용이 많이 드는 것을 볼 수 있습니다.
이렇게 offset이 점점 커지게 된다면 아래와 같이 조회 비용이 증가하게 됩니다.

아래는 이러한 offset의 한계를 해결하기 위한 방법들입니다.
JOIN
SELECT * FROM orders as p inner JOIN ( SELECT orders_id FROM orders LIMIT 10000 offset 10000000 ) AS t ON p.orders_id = t.orders_id;
정렬 순서를 기본으로 하면 속도가 줄긴 했지만 크게 변하지 않은 것을 확인할 수 있습니다. 아래는 price로 정렬순서를 준 케이스입니다.
SELECT * FROM orders as p inner JOIN ( SELECT orders_id FROM orders order by price LIMIT 10000 offset 10000000 ) AS t ON p.orders = t.orders;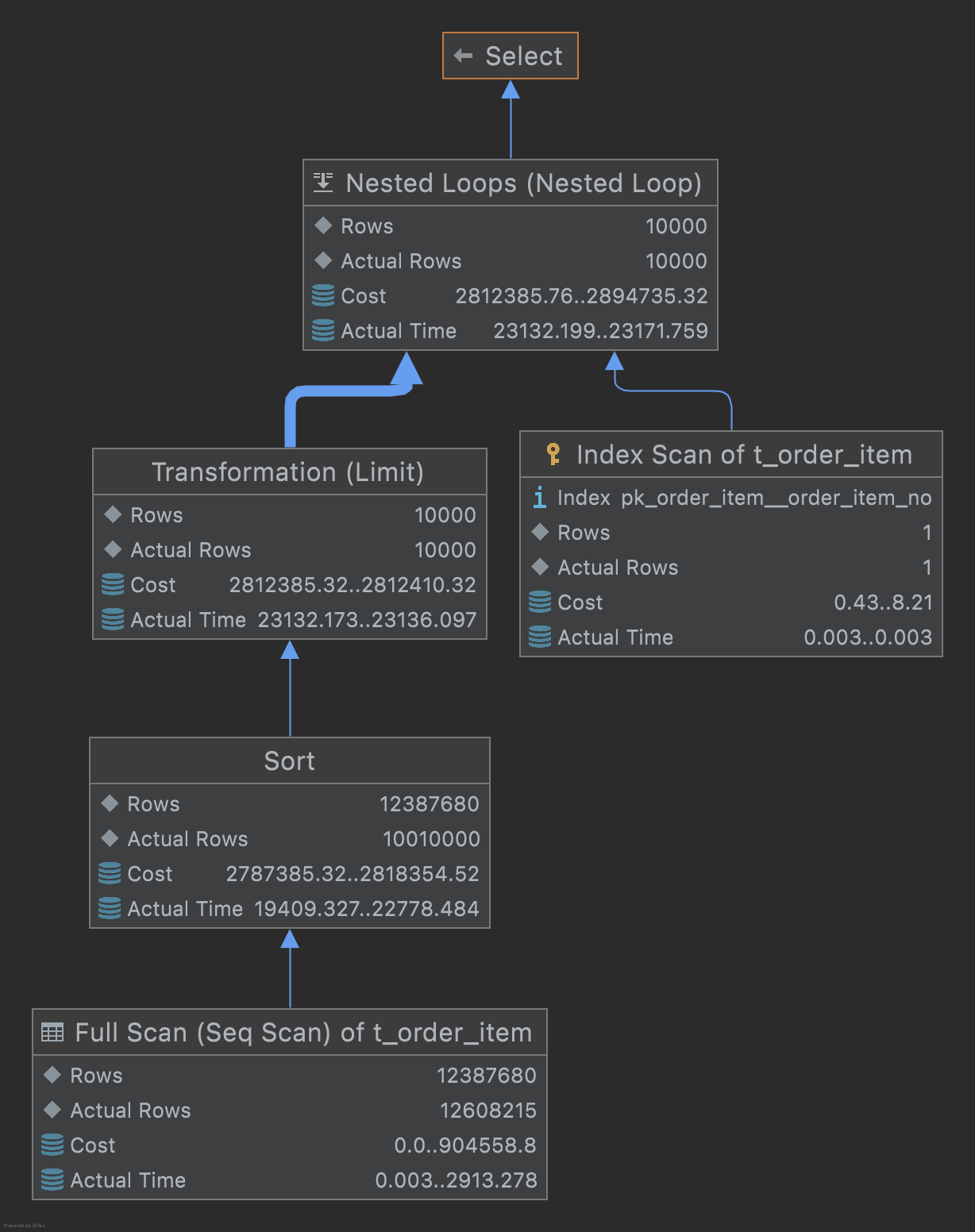
위의 기본 쿼리와 차이점은 full scan 후, 모든 데이터가 아닌 pk(orders_id)만 정렬을 진행합니다. pk는 보통 클러스터 인덱스로 잡혀 있으므로 빠르게 진행이 됩니다. 이렇게 정렬을 진행한 다음, pk 기준으로 join을 진행하므로 기존 offset보다 빠르게 진행할 수 있고 평균적인 속도를 보여줍니다.
INDEX(PK) range query
이 방법은 DB 마이그레이션과 같은 특수한 상황에서 유용하게 사용할 수 있습니다. 1200만건의 테이블을 다른 DB로 마이그레이션을 해야 된다고 한다면 pk를 사용해 range query로 속도를 극대화 시킬 수 있습니다.
select * from orders where orders_id between 10000000 and 10010000;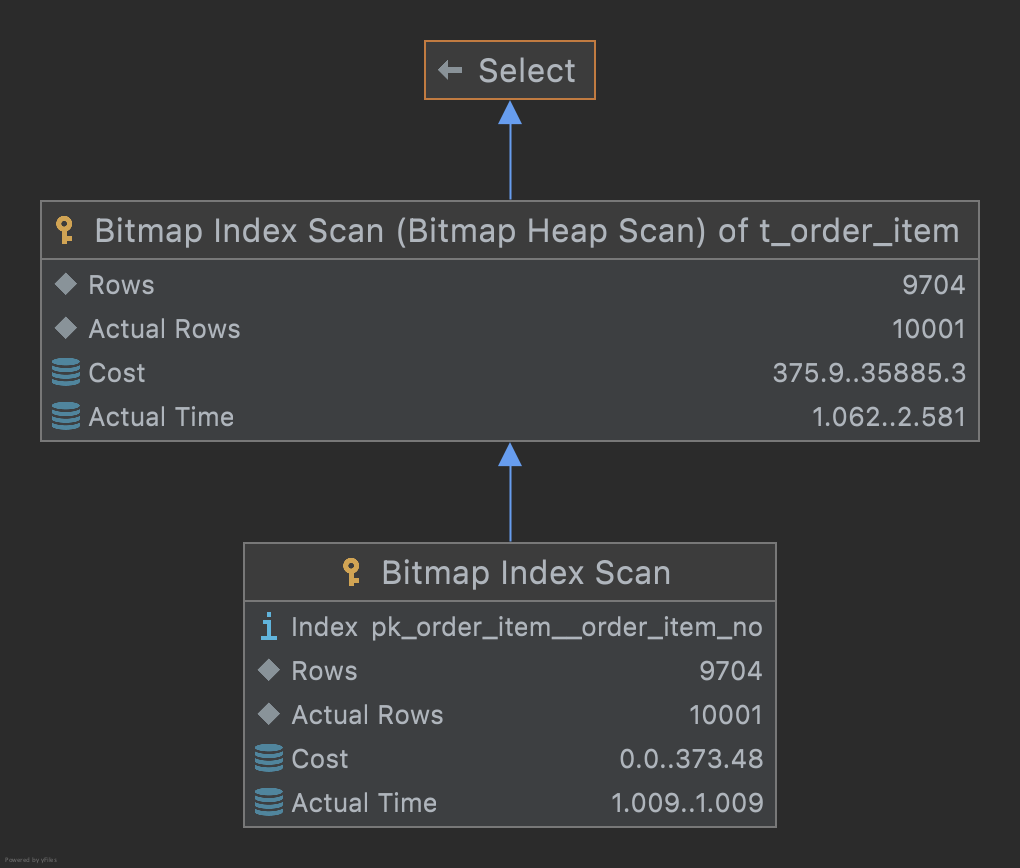
min, max 함수로 pk의 처음과 끝을 가져온 다음, range query를 진행한다면 조건절로 10000건씩 잘라서 가져온다면 limit, offset보다 더 빠르게 처리할 수 있습니다.