-
[Bigquery] Search IndexDB/Bigquery 2024. 7. 8. 01:33
개요
BigQuery는 검색 색인을 사용하여 플랫폼 하나에서 강력한 열 저장과 텍스트 검색을 제공하므로 이를 통해 개별 데이터 행을 찾아야 할 때 효율적으로 행을 조회할 수 있습니다.
검색 색인을 사용하면 쿼리 성능을 크게 높일 수 있습니다. 처리된 바이트 및 슬롯 밀리초의 절감 효과는 스캔되는 데이터가 적어서 검색 결과 수가 테이블의 총 행 수에서 상대적으로 적은 비율을 차지할 때 극대화됩니다.
BigQuery는 색인을 저장하고 관리하고 현재(2024-07-07) 검색 색인은 문자열 뿐만 아니라 시간과 정수형 타입도 적용할 수 있고
SEARCH함수나 =, in, like와 같은 연산자를 사용해 빠르고 효율적으로 검색할 수 있습니다.사용 사례
BigQuery 검색 색인을 사용하면 다음 태스크를 수행할 수 있습니다.
- BigQuery 테이블에 저장된 시스템, 네트워크 또는 애플리케이션 로그 검색
- 규제 프로세스를 준수하기 위해 삭제할 데이터 요소 식별
- 개발자 문제 해결 지원
- 보안 감사 수행
- 매우 까다로운 검색 필터가 필요한 대시보드 생성
- 일치검색을 위해 사전 처리된 데이터 검색
제한사항
- 뷰 또는 구체화된 뷰에서 직접 검색 색인을 만들 수 없지만 색인이 생성된 테이블 뷰이면 기본 검색 색인을 활용할 수 있음
- 검색 색인을 만든 후 테이블의 이름을 변경하면 색인이 무효화됨
SEARCH함수는 점 조회를 위해 설계되었습니다. 퍼지 검색, 오타 수정, 와일드 카드, 기타 유형의 문서 검색은 제공되지 않음- 검색 색인의 범위가 100%가 아니더라도
INFORMATION_SCHEMA.SEARCH_INDEXES뷰에 보고된 모든 색인 스토리지에 대한 요금이 부과됨 SEARCH함수가 포함된 쿼리는 BigQuery BI Engine에 의해 가속화되지 않음- 검색 색인은 색인이 생성된 테이블이 DML 문으로 수정될 경우에는 사용되지 않지만
SEARCH함수가 DML 문에서 서브 쿼리의 일부일 경우에는 사용할 수 있음- 다음 쿼리에서는 검색 색인이 사용되지 않습니다.
DELETE FROM my_dataset.indexed_table WHERE SEARCH(user_id, '123');- 다음 쿼리에서는 검색 색인을 사용할 수 있습니다.
DELETE FROM my_dataset.other_table WHERE user_id IN ( SELECT user_id FROM my_dataset.indexed_table WHERE SEARCH(user_id, '123') );
- 쿼리가 구체화된 뷰를 참조할 때는 검색 색인이 사용되지 않음
검색 색인 생성
검색 색인 적용 가능 타입
검색 색인은 현재(2024-07-07) 정수형과 타임스탬프 미리보기를 포함하여 다음과 같은 타입의 색인을 생성할 수 있습니다.
STRINGARRAY<STRING>STRING또는ARRAY<STRING>유형의 중첩된 필드가 하나 이상 포함된STRUCT
JSONINT64TIMESTAMP
검색 색인 텍스트 분석기 선택
텍스트 분석기는 색인 생성 및 검색을 위해 데이터가 토큰화되는 방식을 제어합니다. 검색 색인을 만들 때 사용할 텍스트 분석기 유형은 다음 3가지에서 지정할 수 있습니다.
NO_OP_ANALYZERLOG_ANALYZER(기본값)PATTERN_ANALYZER
LOG_ANALYZER (기본값)
LOG_ANALYZER 분석기는 구분 기호가 나타나면 입력 텍스트를 용어(토큰)로 추출하고 구분 기호를 삭제한 후 결과에서 대문자를 소문자로 변경합니다.
세부정보:
- 용어에 있는 대문자는 소문자로 바뀌지만 127보다 큰 ASCII 값은 그대로 유지
- 공백, 마침표, 글자가 아닌 문자와 같은 구분 기호 중 하나가 나타나면 텍스트가 개별 용어로 분할
- 이러한 기본 구분 기호를 사용하지 않으려면 텍스트 분석기 옵션으로 사용할 특정 구분 기호를 지정
[ ] < > ( ) { } | ! ; , ' " * & ? + / : = @ . - $ % \ _ \n \r \s \t %21 %26 %2526 %3B %3b %7C %7c %20 %2B %2b %3D %3d %2520 %5D %5d %5B %5b %3A %3a %0A %0a %2C %2c %28 %29- 토큰 필터를 지원하고
token_filters옵션이 지정되어 있지 않은 경우 기본적으로 ASCII 소문자 정규화가 사용
이 분석기는 머신 생성 로그에 잘 작동하며 IP 주소 또는 이메일과 같은 관측 가능성 데이터에서 일반적으로 발견되는 토큰에 대한 특수 규칙을 갖고 있습니다.
예시)
SELECT TEXT_ANALYZE( 'I like pie, you like-pie, they like 2 PIEs.', analyzer=>'LOG_ANALYZER' ) AS results /*---------------------------------------------------------------------------* | results | +---------------------------------------------------------------------------+ | [ 'i', 'like', 'pie', 'you', 'like', 'pie', 'they', 'like', '2', 'pies' ] | *---------------------------------------------------------------------------*/ SELECT TEXT_ANALYZE( 'I like pie, you like-pie, they like 2 PIEs.', analyzer=>'LOG_ANALYZER', analyzer_options=>'{"delimiters": [",", ".", "-"]}' ) AS results /*-------------------------------------------------------* | results | +-------------------------------------------------------+ | ['i like pie', 'you like', 'pie', 'they like 2 pies]' | *-------------------------------------------------------*/NO_OP_ANALYZER
NO_OP_ANALYZER 분석기는 입력 텍스트를 단일 용어(토큰)로 추출하는 무연산 분석기입니다. 결과 용어에는 서식이 적용되지 않습니다. 즉, 정확하게 일치해야 하는 데이터가 사전 처리된 경우 NO_OP_ANALYZER를 사용합니다.
예시)
SELECT TEXT_ANALYZE( 'I like pie, you like-pie, they like 2 PIEs.', analyzer=>'NO_OP_ANALYZER' ) AS results /*-----------------------------------------------* | results | +-----------------------------------------------+ | 'I like pie, you like-pie, they like 2 PIEs.' | *-----------------------------------------------*/PATTERN_ANALYZER
PATTERN_ANALYZER 분석기는 re2 정규 표현식을 사용하여 비정형 텍스트에서 용어(토큰)를 추출합니다.
이 분석기는 입력 텍스트의 왼쪽에서 정규 표현식과 일치하는 첫 번째 용어를 찾아 출력에 추가합니다. 그런 다음 새로 찾은 용어까지 입력 텍스트의 프리픽스를 삭제합니다. 이 프로세스는 입력 텍스트가 비어 있을 때까지 반복됩니다.
기본적으로 정규 표현식
\b\w{2,}\b가 사용됩니다.- 이 정규 표현식은 최소 2개 문자가 포함된 비유니코드 단어와 일치
- 다른 정규 표현식을 사용하려면
patterns옵션을 참조: https://cloud.google.com/bigquery/docs/reference/standard-sql/text-analysis?hl=ko#pattern_analyzer_options
또한 토큰 필터를 지원하고
token_filters옵션이 지정되어 있지 않은 경우 기본적으로 ASCII 소문자 정규화가 사용됩니다.token_filters옵션: https://cloud.google.com/bigquery/docs/reference/standard-sql/text-analysis?hl=ko#token_filters_option
예시)
-- 기본 정규 표현식이 사용되므로 두 개 이상의 문자가 있는 단어만 용어로 포함(i 및 2는 결과에 표시되지 않음). 또한 결과가 소문자 SELECT TEXT_ANALYZE( 'I like pie, you like-pie, they like 2 PIEs.', analyzer=>'PATTERN_ANALYZER' ) AS results /*----------------------------------------------------------------* | results | +----------------------------------------------------------------+ | ['like', 'pie', 'you', 'like', 'pie', 'they', 'like', 'pies' ] | *----------------------------------------------------------------*/ SELECT TEXT_ANALYZE( 'I like pie, you like-pie, they like 2 PIEs.', analyzer=>'PATTERN_ANALYZER', analyzer_options=>''' { "patterns": ["[a-zA-Z]*"], "token_filters": [ { "normalizer": { "mode": "LOWER" } }, { "stop_words": ["they", "pie"] } ] } ''' ) AS results /*----------------------------------------------* | results | +----------------------------------------------+ | ['i', 'like', 'you', 'like', 'like, 'PIEs' ] | *----------------------------------------------*/검색 색인 생성 쿼리
CREATE TABLE dataset.my_table( a STRING, b INT64, c STRUCT <d INT64, e ARRAY<STRING>, f STRUCT<g STRING, h INT64>>) AS SELECT 'hello' AS a, 10 AS b, (20, ['x', 'y'], ('z', 30)) AS c;와 같은 테이블이 있다고 가정할 때, 다음과 같이 다양한 방법으로 검색 색인을 생성할 수 있습니다. 10GB보다 작은 테이블에 검색 색인을 만들면 색인이 채워지지 않습니다. 마찬가지로 색인이 생성된 테이블에서 데이터를 삭제하고 테이블 크기가 10GB 미만이 되면 색인이 일시적으로 사용 중지됩니다.
생성 이후 적용까지 시간이 걸릴 수 있으므로 다음 쿼리를 실행하여 coverage_percentage 가 100인지 확인이 필요합니다.
SELECT * FROM 프로젝트.데이터셋.INFORMATION_SCHEMA.SEARCH_INDEXES WHERE index_status = 'ACTIVE';모든 컬럼, 모든 타입의 검색 색인 생성
CREATE SEARCH INDEX my_all_cloumns_index ON dataset.my_table(ALL COLUMNS) OPTIONS (analyzer = 'LOG_ANALYZER', data_types = ['STRING', 'INT64', 'TIMESTAMP']);ALL COLUMNS에서 검색 색인을 만들면 테이블의 모든STRING또는JSON데이터가 색인 생성됩니다. 테이블에 이러한 데이터가 없으면(예: 모든 열에 DATE일 경우) 색인 생성이 실패합니다. 색인을 생성할STRUCT열을 지정하면 모든 중첩 하위 필드의 색인이 생성됩니다.특정 컬럼, 특정 타입의 검색 색인 생성
CREATE SEARCH INDEX my_c_index ON dataset.my_table(c) OPTIONS (analyzer = 'LOG_ANALYZER', data_types = ['INT64']); CREATE SEARCH INDEX my_a_index ON dataset.my_table(a) OPTIONS (analyzer = 'LOG_ANALYZER', data_types = ['STRING']);검색 색인 관리
색인 새로고침 이해하기
검색 색인은 BigQuery에서 완전하게 관리되며 테이블이 변경되면 자동으로 새로고침됩니다. 테이블에서 다음과 같이 스키마를 변경하면 전체 새로 고침이 트리거될 수 있습니다.
- 색인 생성이 가능한 새 열이
ALL COLUMNS에서 검색 색인이 있는 테이블에 추가 - 테이블 스키마 변경으로 인해 색인이 생성된 열이 업데이트
테이블에서 색인이 생성된 유일한 열을 삭제하거나 테이블 자체의 이름을 바꾸면 검색 색인이 자동으로 삭제됩니다.
검색 색인은 큰 테이블을 위해 설계되었습니다. 10GB보다 작은 테이블에 검색 색인을 만들 경우 색인이 채워지지 않습니다. 마찬가지로 색인이 생성된 테이블에서 데이터를 삭제하고 테이블 크기가 10GB 미만이 되면 색인이 일시적으로 사용 중지됩니다. 이 경우 검색 쿼리에 색인이 사용되지 않고
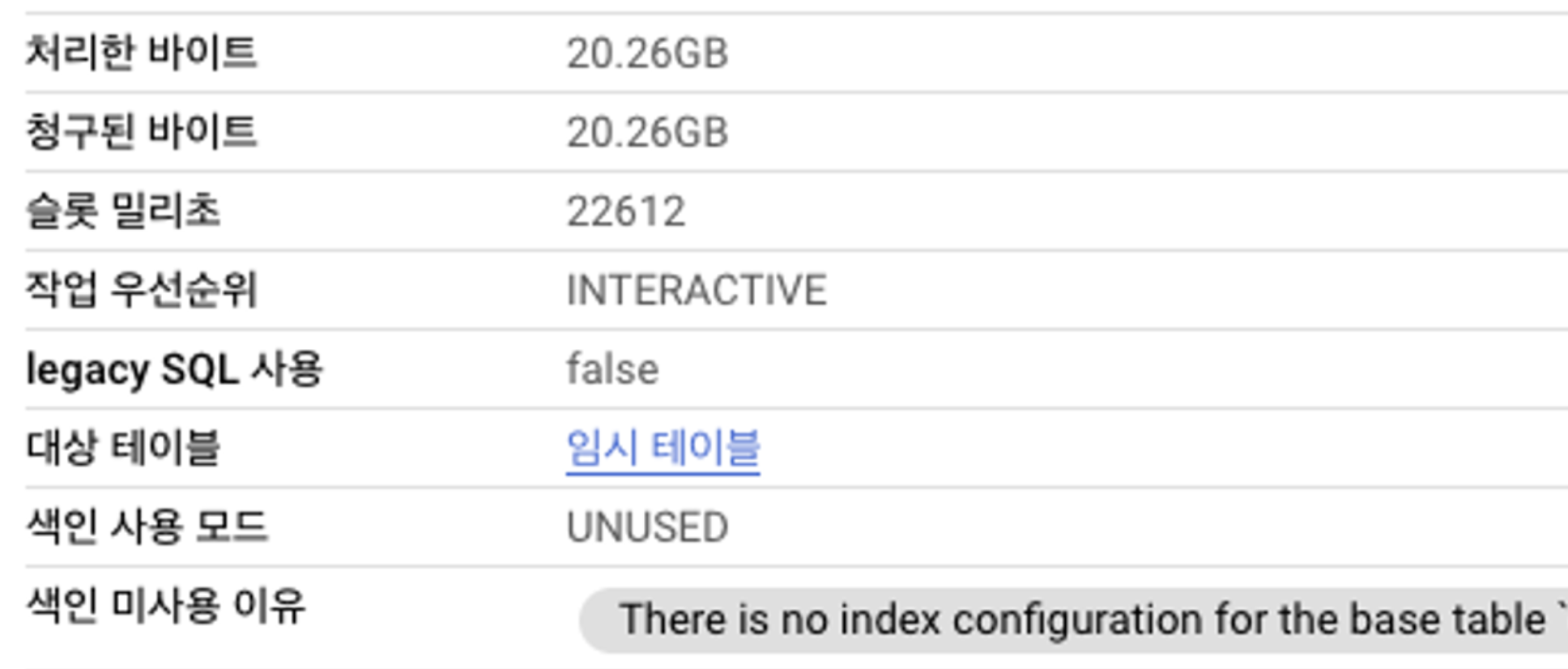
IndexUnusedReason코드가BASE_TABLE_TOO_SMALL입니다. 이러한 결과는 색인 관리 작업에 자체 예약을 사용하는지 여부에 관계없이 발생합니다. 색인 생성된 테이블의 크기가 10GB를 초과하면 색인이 자동으로 채워집니다. 검색 색인이 채워지고 활성화되기 전에는 스토리지 비용이 청구되지 않습니다.검색 색인 정보 가져오기
INFORMATION_SCHEMA를 쿼리하여 검색 색인의 존재 및 준비 여부를 확인할 수 있습니다. 검색 색인에 대한 메타데이터가 포함된 두 개의 뷰가 있습니다.INFORMATION_SCHEMA.SEARCH_INDEXES뷰에는 데이터 세트에 생성된 각 검색 색인에 대한 정보가 있습니다.INFORMATION_SCHEMA.SEARCH_INDEX_COLUMNS뷰에는 데이터 세트에 있는 각 테이블의 열 중 색인이 생성되는 열에 대한 정보가 있습니다.다음 예시는
my_project프로젝트에 위치한 데이터 세트my_dataset에 있는 테이블의 모든 활성 검색 색인을 보여줍니다. 여기에는 검색 색인의 이름, 검색 색인을 만드는 데 사용된 DDL 문, 적용 범위 비율, 텍스트 분석기가 포함됩니다. 색인이 생성된 기본 테이블이 10GB 미만이면 색인이 채워지지 않으며, 이 경우coverage_percentage는 0입니다.SELECT table_name, index_name, ddl, coverage_percentage, analyzer FROM my_project.my_dataset.INFORMATION_SCHEMA.SEARCH_INDEXES WHERE index_status = 'ACTIVE';또한 검색 색인 생성 성공 시, 생성된 색인의 저장 용량도 해당 뷰에서 확인할 수 있습니다.

다음 쿼리는
INFORMATION_SCHEMA.SEARCH_INDEX_COUMNS뷰를INFORMATION_SCHEMA.SEARCH_INDEXES및INFORMATION_SCHEMA.COLUMNS뷰와 조인하여 검색 색인 상태 및 각 열의 데이터 유형을 포함합니다.SELECT index_columns_view.index_catalog AS project_name, index_columns_view.index_SCHEMA AS dataset_name, indexes_view.TABLE_NAME AS table_name, indexes_view.INDEX_NAME AS index_name, indexes_view.INDEX_STATUS AS status, index_columns_view.INDEX_COLUMN_NAME AS column_name, index_columns_view.INDEX_FIELD_PATH AS field_path, columns_view.DATA_TYPE AS data_type FROM mydataset.INFORMATION_SCHEMA.SEARCH_INDEXES indexes_view INNER JOIN mydataset.INFORMATION_SCHEMA.SEARCH_INDEX_COLUMNS index_columns_view ON indexes_view.TABLE_NAME = index_columns_view.TABLE_NAME AND indexes_view.INDEX_NAME = index_columns_view.INDEX_NAME LEFT OUTER JOIN mydataset.INFORMATION_SCHEMA.COLUMNS columns_view ON indexes_view.INDEX_CATALOG = columns_view.TABLE_CATALOG AND indexes_view.INDEX_SCHEMA = columns_view.TABLE_SCHEMA AND index_columns_view.TABLE_NAME = columns_view.TABLE_NAME AND index_columns_view.INDEX_COLUMN_NAME = columns_view.COLUMN_NAME ORDER BY project_name, dataset_name, table_name, column_name; /* +------------+------------+----------+------------+--------+-------------+------------+---------------------------------------------------------------+ | project | dataset | table | index_name | status | column_name | field_path | data_type | +------------+------------+----------+------------+--------+-------------+------------+---------------------------------------------------------------+ | my_project | my_dataset | my_table | my_index | ACTIVE | a | a | STRING | | my_project | my_dataset | my_table | my_index | ACTIVE | c | c.e | STRUCT<d INT64, e ARRAY<STRING>, f STRUCT<g STRING, h INT64>> | | my_project | my_dataset | my_table | my_index | ACTIVE | c | c.f.g | STRUCT<d INT64, e ARRAY<STRING>, f STRUCT<g STRING, h INT64>> | +------------+------------+----------+------------+--------+-------------+------------+---------------------------------------------------------------+ */색인 관리 옵션
색인을 만들고 BigQuery가 이를 유지보수하도록 할 때는 다음 두 가지 옵션이 있습니다.
- 기본 공유 슬롯 풀 사용
- 자체 예약 사용
공유 슬롯 사용
색인 생성에 자체 예약을 사용하도록 프로젝트를 구성하지 않은 경우 색인 관리는 다음과 같은 제약조건에 따라 무료 공유 슬롯 풀에서 처리됩니다.
데이터를 테이블에 추가하여 색인이 생성된 테이블의 총 크기가 조직의 한도를 초과할 경우 BigQuery가 색인이 생성된 모든 테이블의 색인 관리를 일시중지합니다.
- 빅쿼리 검색 색인 기본 한도: https://cloud.google.com/bigquery/quotas?hl=ko#index_limits
이 경우
INFORMATION_SCHEMA.SEARCH_INDEXES뷰의index_status필드에PENDING DISABLEMENT가 표시되고 색인이 삭제 큐에 추가됩니다. 사용 중지 대기 중인 색인은 쿼리에 계속 사용되며 색인 스토리지 요금이 부과됩니다. 색인이 삭제되면index_status필드에 색인이TEMPORARILY DISABLED로 표시됩니다. 이 상태에서는 쿼리에 색인이 사용되지 않고 색인 스토리지 요금이 청구되지 않습니다. 여기에서IndexUnusedReason코드는BASE_TABLE_TOO_LARGE입니다.테이블에서 데이터를 삭제하고 색인이 생성된 테이블의 총 크기가 조직별 한도 미만이 되면 색인이 생성된 모든 테이블의 색인 관리가 다시 시작됩니다.
INFORMATION_SCHEMA.SEARCH_INDEXES뷰의index_status필드는ACTIVE이고 쿼리에서 색인을 사용할 수 있으며 색인 스토리지에 대한 요금이 부과됩니다.BigQuery는 공유 풀의 사용 가능한 용량 또는 표시된 색인 생성의 처리량을 보장하지 않습니다. 프로덕션 애플리케이션의 경우 색인 처리를 위해 전용 슬롯을 사용할 수 있습니다.
자체 예약 사용
기본 공유 슬롯 풀을 사용하는 대신 자체 예약을 지정하여 테이블의 색인을 지정할 수 있습니다. 자체 예약을 사용하면 생성, 새로고침, 백그라운드 최적화와 같은 색인 관리 작업의 예측 가능한 일관된 성능을 보장할 수 있습니다.
- 예약에서 색인 생성 작업을 실행할 때는 테이블 크기 한도가 없음
- 자체 예약을 사용하면 색인을 유연하게 관리할 수 있음
- 매우 큰 색인을 만들거나 색인 생성된 테이블에 주요 업데이트를 수행해야 하는 경우 일시적으로 할당에 슬롯을 더 추가할 수 있음
즉, 빅쿼리 슬롯 약정을 사용하는 방식입니다.
검색 색인 사용, 미사용 사유 코드
검색 색인 사용, 미사용은 호출 후 다음과 같은 빅쿼리 콘솔에서
색인 사용/미사용 모드로 확인할 수 있습니다.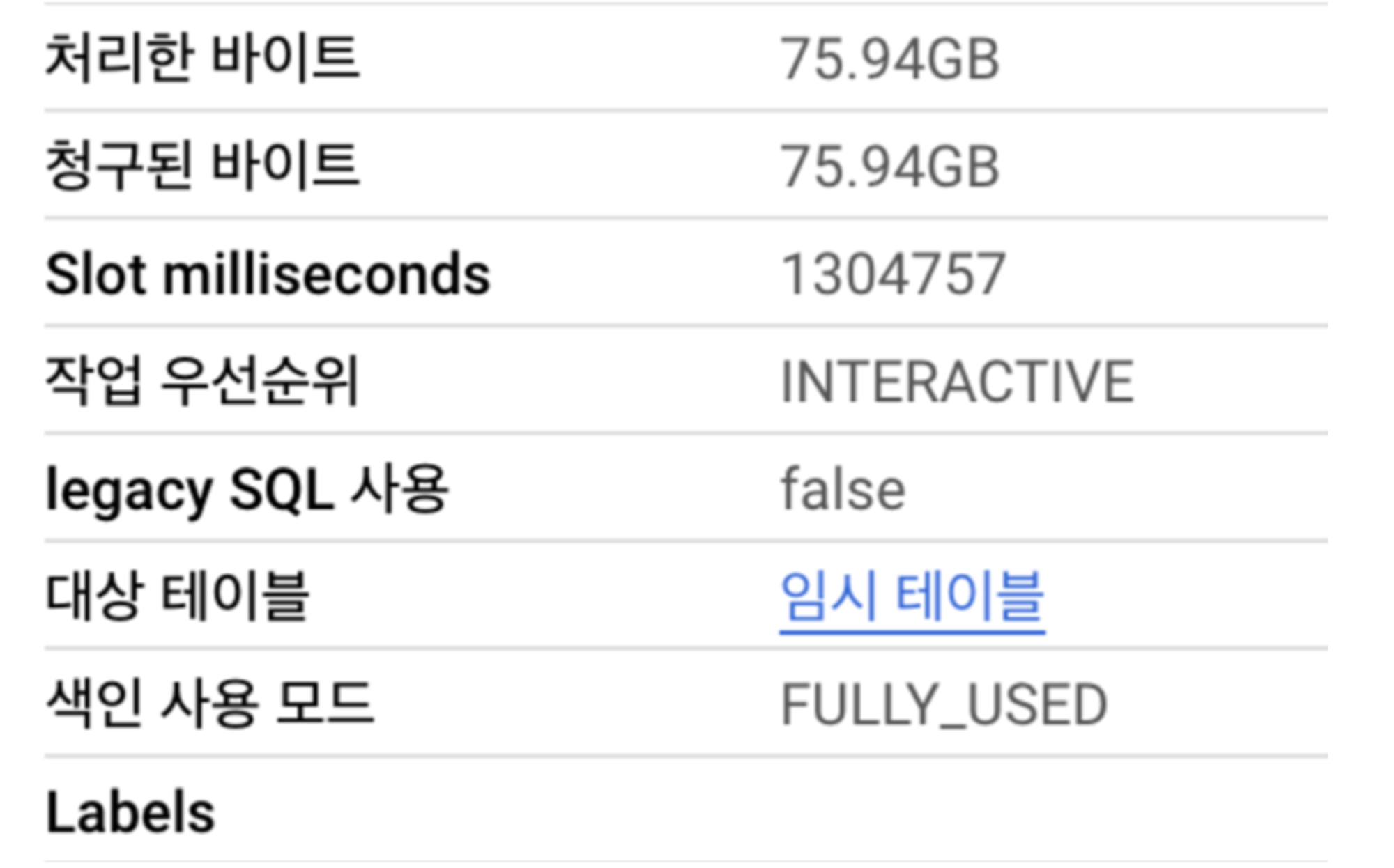
색인 사용 모드

색인 미사용 코드

검색 색인 삭제
검색 색인이 더 이상 필요하지 않거나 테이블에서 색인을 생성할 열을 변경하려면 현재 테이블에 있는 색인을 삭제하면 됩니다. 이를 위해서는
DROP SEARCH INDEXDDL 문을 사용합니다.색인이 생성된 테이블을 삭제하면 색인이 자동으로 삭제됩니다.
DROP SEARCH INDEX my_index ON dataset.simple_table;검색 색인 테스트
테스트 환경은 다음과 같습니다.
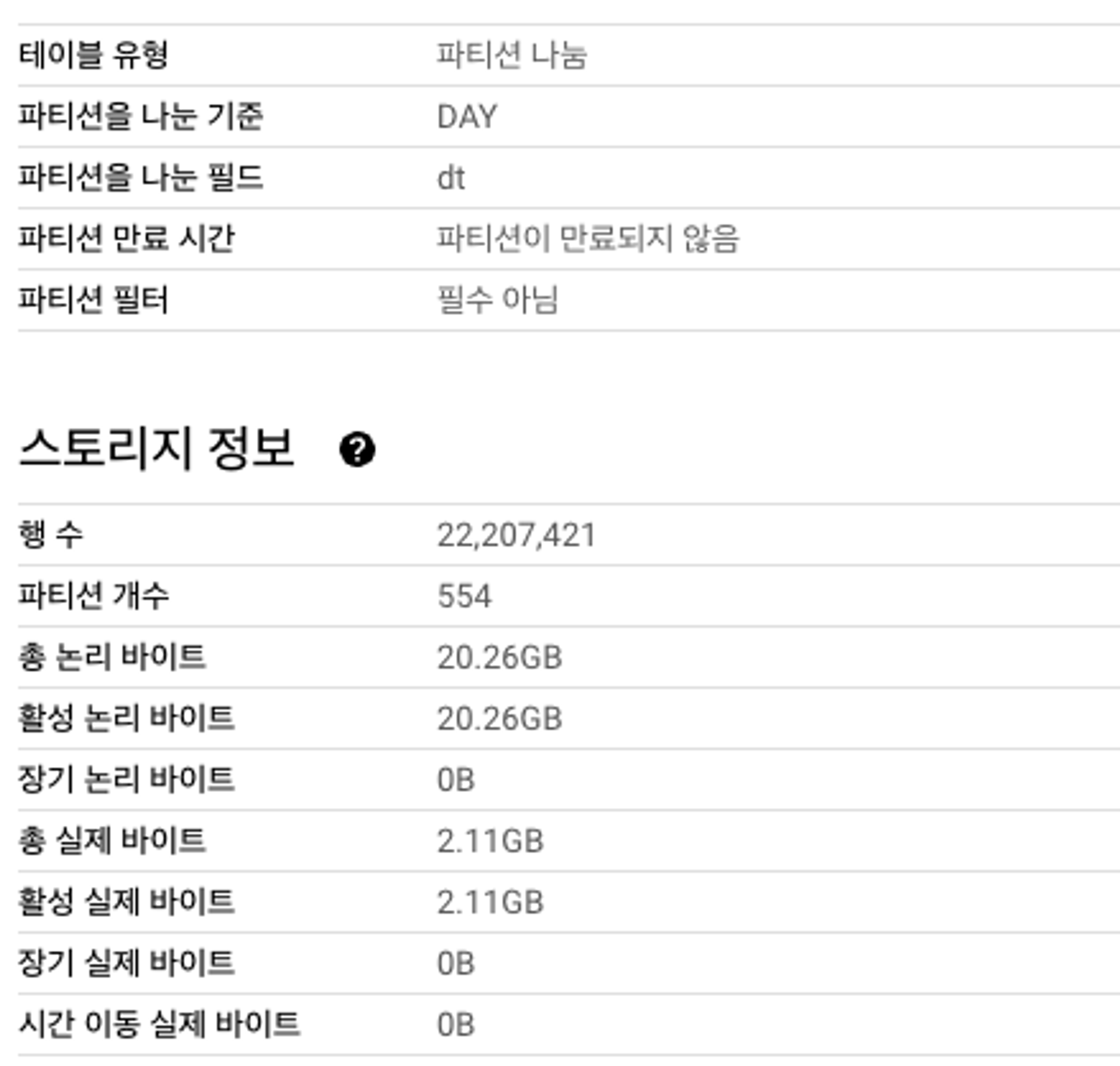
검색 색인이 되지 않은 경우, 대부분 다음과 같습니다.
검색 색인 X 테이블
LOG_ANALYZER 분석기 테스트
CREATE SEARCH INDEX my_all_cloumns_index ON dataset.my_table(ALL COLUMNS) OPTIONS (analyzer = 'LOG_ANALYZER', data_types = ['STRING', 'INT64', 'TIMESTAMP']);문자열 = 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '상품이름' ; -- 결과 0건검색 색인 테이블
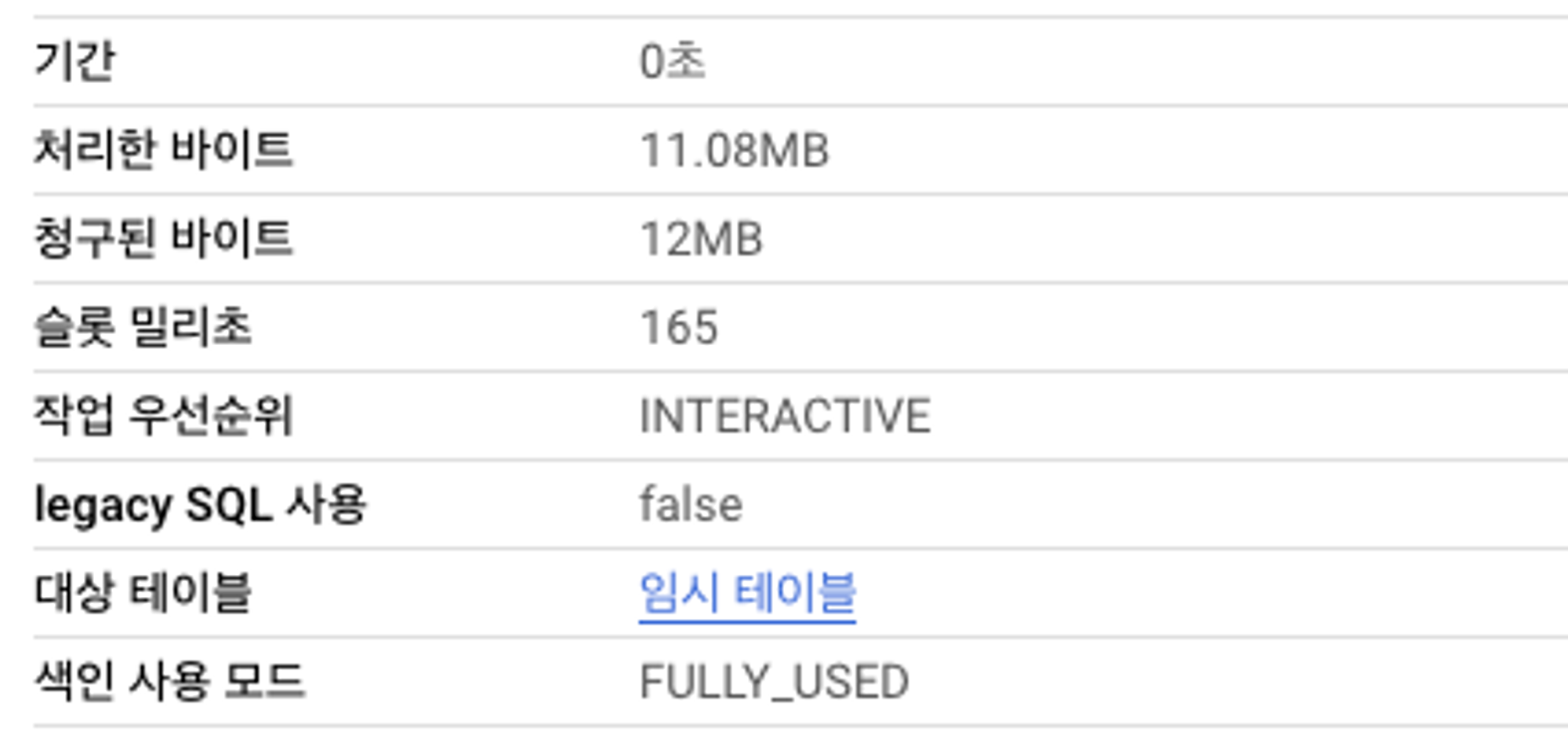
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '특정 상품 이름명' ; -- 결과 434건검색 색인 테이블
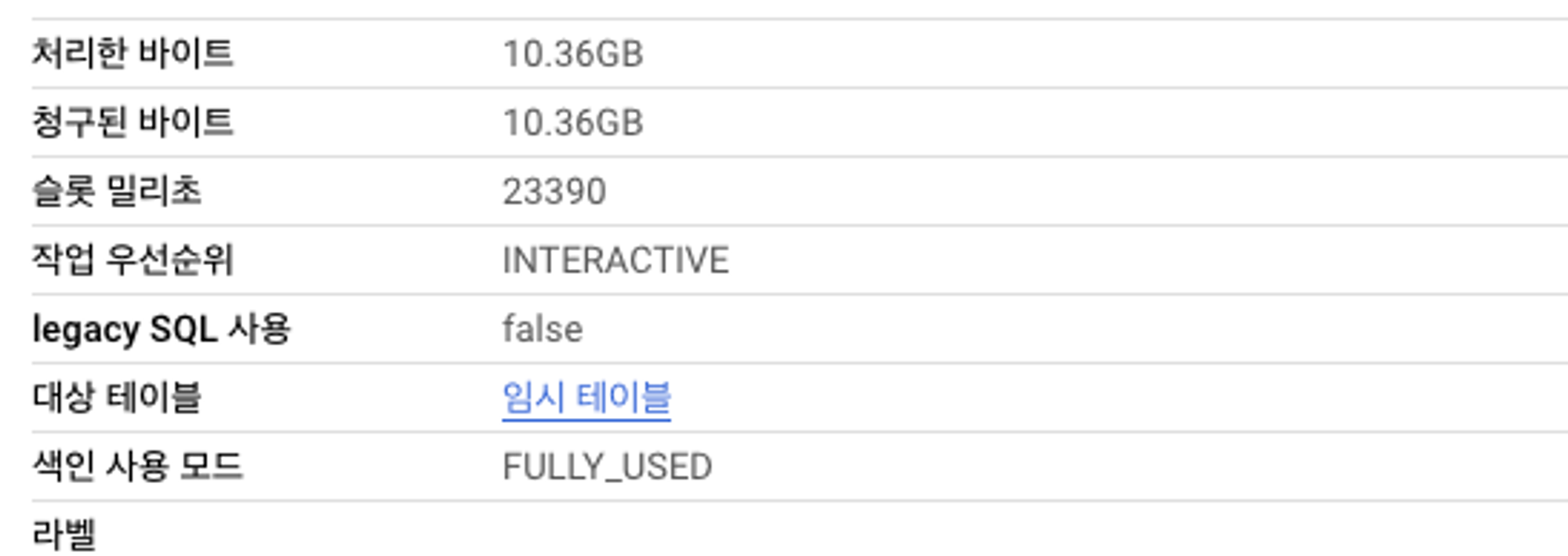
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '특정 상품 이' ; -- 결과 0건검색 색인 테이블

문자열 like 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name like '상품이름%' ; -- 결과 0건검색 색인 테이블

SELECT * FROM `프로젝트.데이터셋.no_search_index_test` WHERE dt >= "2023-01-01" and item_name like '특정 상품 이%' ; -- 결과 35873건검색 색인 테이블

정수형 = 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and id = 12521 ; -- 결과 0건검색 색인 테이블

SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and id = 1590 ; -- 결과 57386건검색 색인 테이블

NO_OP_ANALYZER 분석기 테스트
CREATE SEARCH INDEX my_all_cloumns_index ON dataset.my_table(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER', data_types = ['STRING', 'INT64', 'TIMESTAMP']);문자열 = 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '상품이름' ; -- 결과 0건검색 색인 테이블

SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '특정 상품 이름 명' ; -- 결과 434건검색 색인 테이블
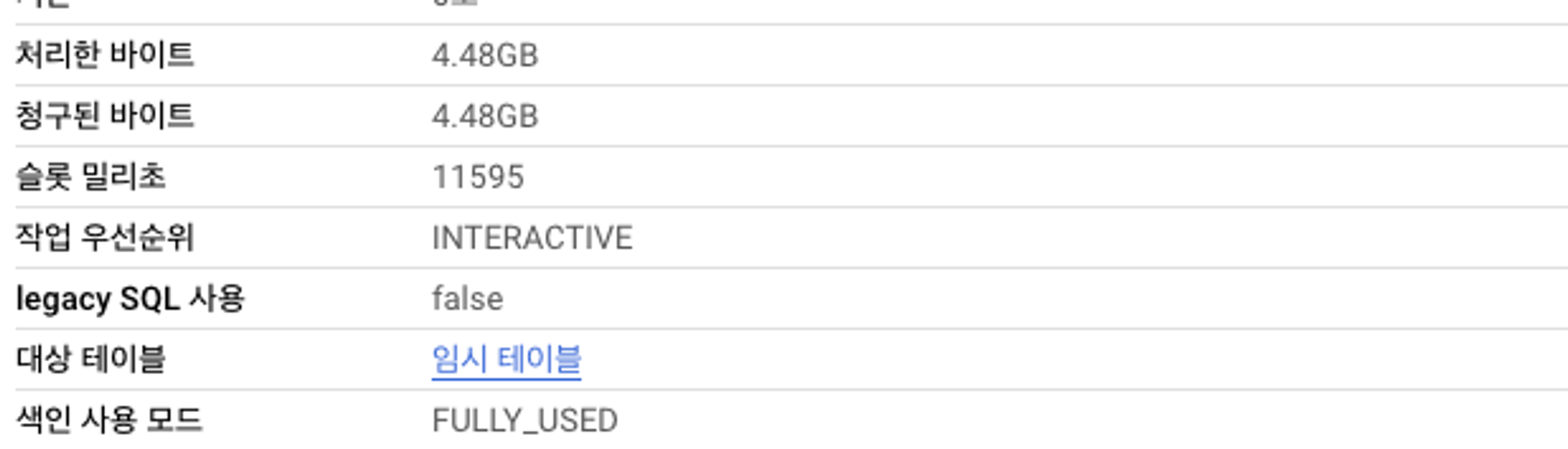
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name = '특정 상품 이' ; -- 결과 0건검색 색인 테이블

문자열 like 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and item_name like '상품이름%' ; -- 결과 0건검색 색인 테이블

SELECT * FROM `프로젝트.데이터셋.no_search_index_test` WHERE dt >= "2023-01-01" and item_name like '특정 상품 이%' ; -- 결과 35873건검색 색인 테이블

정수형 = 사용
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and id = 12521 ; -- 결과 0건검색 색인 테이블
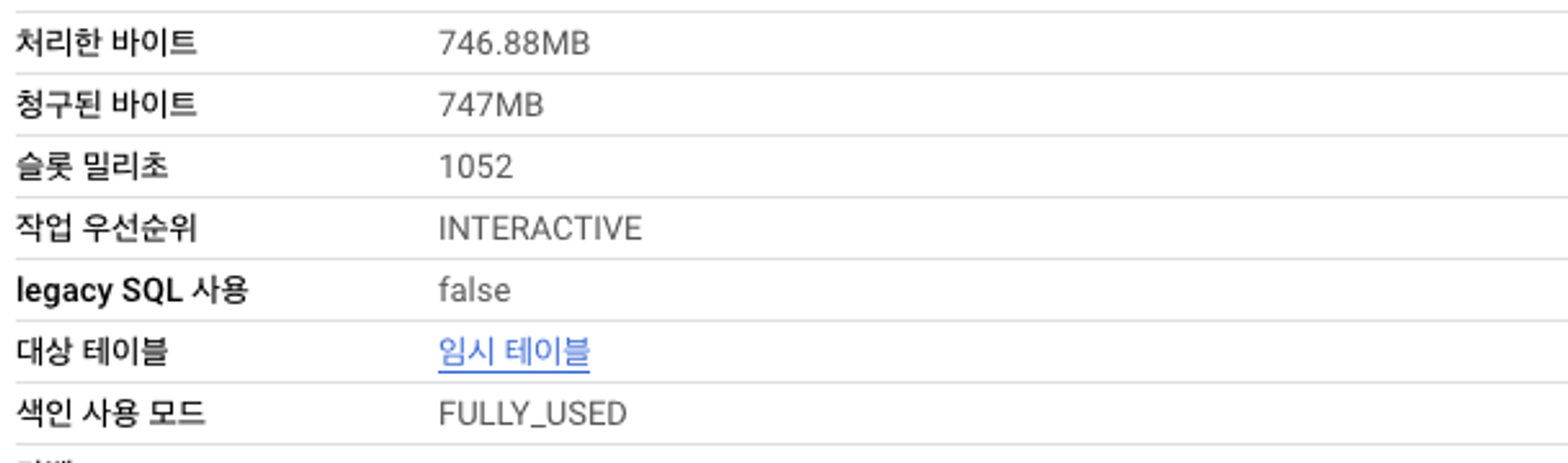
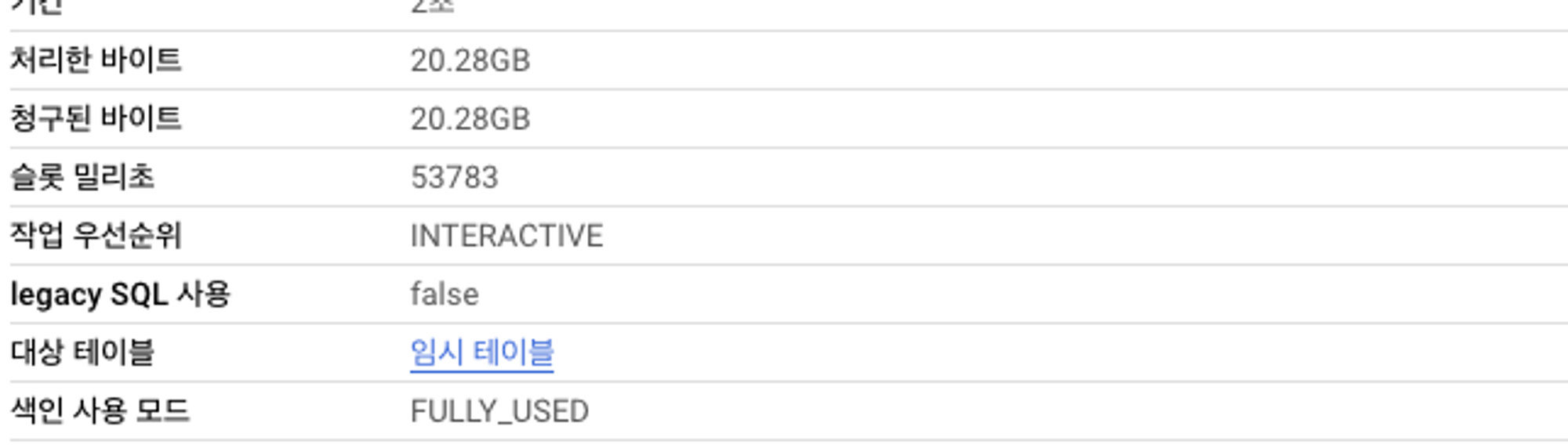
SELECT * FROM `프로젝트.데이터셋.search_index_test` WHERE dt >= "2023-01-01" and id = 1590 ; -- 결과 57386건검색 색인 테이블
요약
- 검색 색인은 큰 테이블을 위해 설계되었으므로 검색 색인으로 인한 성능 이점은 테이블 크기에 따라 증가함
- 고유 값 수가 적은 열은 색인 효과를 받지 못할 경우가 크므로 생성 X
- 조회되는 결과가 많거나 분석기에 의해 토큰이 많이 색인되어있는 경우, 절감 효과를 받지 못함
ALL COLUMNS에서 검색 색인을 만들 때는 주의가 필요STRING또는JSON데이터가 포함된 열을 추가할 때마다 색인이 생성- = 필요한 컬럼만 지정해서 인덱스 생성
- 분석기에 따라 색인의 저장 용량이 달라지며 색인 효과도 달라짐
- 검색 인덱스 생성시 저장되는 스토리지는 무조건 logical_storage에만 저장되는지 데이터셋의 저장 방식을 따라가는지 확인이 필요함
LOG_ANALYZER보다NO_OP_ANALYZER가 더 큼NO_OP_ANALYZER는 값을 그대로 저장하지만LOG_ANALYZER는 옵션에 따라 삭제되는 데이터가 존재
- 클러스터링키 + 검색 색인은 특수한 경우에만 시너지가 나고 대부분은 클러스터링 키만 적용될 것으로 예상
- item_name을 클러스터키로 걸었을 때,
item_name like 'LEXON 상품명%'한다면 클러스터링키가 먼저 적용되어 해당되는 레코드의 범위를 찾은 다음, 검색 색인이 적용되지 않을까 생각 중
- item_name을 클러스터키로 걸었을 때,
- 색인을 만들고 BigQuery가 이를 유지보수할 때, 슬롯 약정을 거는 것이 이상적이나 비용 이슈가 있다면 빅쿼리의 검색 색인 한도를 올리고 공유 슬롯을 사용하는 것이 좋아보임
레퍼런스
관련 블로그
- https://cloud.google.com/blog/products/data-analytics/bigquery-optimization-with-search-indexes-expanded-preview/?hl=en
- https://cloud.google.com/blog/products/data-analytics/bigquery-text-analysis-and-preprocessing-for-your-data/?hl=en
- https://cloud.google.com/blog/products/data-analytics/announcing-bigquery-numeric-search-indexes?hl=en
관련 공식 문서
- https://cloud.google.com/bigquery/docs/search-intro?hl=ko
- https://cloud.google.com/bigquery/docs/search?hl=ko
- https://cloud.google.com/bigquery/docs/search-index?hl=ko
- https://cloud.google.com/bigquery/docs/reference/standard-sql/text-analysis?hl=ko
- https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#indexusagemode_1
- https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#Code_1