-
[Bigquery] 샤드, 파티션 테이블, 클러스터링 파악하기DB/Bigquery 2023. 11. 19. 03:44
테이블 분할
많은 데이터가 존재하는 테이블을 쿼리하면 두 가지 문제 중 하나가 발생합니다. 데이터베이스에 스캔하고 집계할 데이터가 많기 때문에 매우 어려워지거나 비용이 매우 많이 듭니다.
따라서 빅쿼리는 파티션이라는 기능을 제공하고 있고 세그먼트로 나누어 데이터를 더 쉽게 관리하게끔 합니다.
샤드 테이블
샤드 테이블은 날짜를 기반해 테이블을 쪼개어 관리할 수 있고 다음과 같은 특성을 가지고 있습니다.
- 동일한 데이터셋에 존재
- 동일한 테이블 스키마
- 동일한 접두사 (= 동일한 테이블명)
- _YYYYMMDD 형식의 접미사
- 예) table_20231119

샤드 테이블은 드롭다운으로 적재되어 있는 일자를 조회할 수 있습니다.

하지만 전체 기간의 테이블 크기와 같은 정보는 세부 정보에서 알 수 없으며 전체 테이블을 삭제하는 것은 귀찮은 작업이 될 수도 있습니다.
조회의 경우, 다음과 같이 union을 사용해 조회할 수도 있고
_table_suffix를 활용해 조회할 수도 있습니다.select * from `example_dataset.date_sharded_20210129` union all select * from `example_dataset.date_sharded_20210130` union all select * from `example_dataset.date_sharded_20210131` 또는 select * from `example_dataset.date_sharded_*` _TABLE_SUFFIX between '20210129' and '20210131'파티션 테이블
파티션을 나눈 테이블은 데이터를 단일 논리 테이블에 저장하면서 효율적으로 쿼리할 수 있습니다. 쿼리 성능을 높일 수 있고 쿼리에서 스캔하는 바이트 수를 줄여 비용을 줄일 수 있습니다.
파티션을 나눈 테이블 소개 | BigQuery | Google Cloud
파티션된 필드를 제대로 적용하려면 상수 표현식(정적 표현)을 사용해야 합니다. 동적 표현식을 사용할 경우, 파티션은 적용되지 않습니다.
SELECT t1.name, t2.category FROM table1 AS t1 INNER JOIN table2 AS t2 ON t1.id_field = t2.field2 WHERE t1.ts = CURRENT_TIMESTAMP()SELECT t1.name, t2.category FROM table1 AS t1 INNER JOIN table2 AS t2 ON t1.id_field = t2.field2 WHERE t1.ts = (SELECT timestamp from table3 where key = 2)또한 파티션 컬럼을 분리하여 필터링해야 합니다. 여러 필드의 데이터를 필요로 하는 필터에서는 파티션이 적용되지 않습니다.
WHERE TIMESTAMP_ADD(partition_datetime, INTERVAL 6 HOUR) > ts2샤드 테이블과 파티션 테이블의 차이점
샤드 테이블은 레거시 기능 중 하나로 빅쿼리의 레거시 SQL에서 일반적으로 사용되었습니다. 빅쿼리는 각 샤드 테이블에 대한 스키마 및 메타데이터의 사본을 유지하고 쿼리된 테이블 각각에 대한 사용 권한을 검증합니다. 또한 단일 쿼리는 1000개 이상의 테이블을 쿼리할 수 없으며 테이블이 연도가 아니라 날짜별로 샤딩된 경우, 쿼리에 제약이 생길 수 있습니다.
클러스터링
파티셔닝과 마찬가지로 클러스터링은 쿼리 시 적은 양의 데이터를 읽을 수 있는 방식으로 빅쿼리에 데이터를 저장하는 방식입니다. 클러스터링이 적용된 테이블은 정렬된 형식을 단일 테이블로 저장합니다. 클러스터링된 테이블에서는 이 테이블을 수정하는 작업과 관련하여 정렬을 유지합니다. 클러스터링된 컬럼을 기준으로 필터링 또는 집계하는 쿼리는 클러스터링된 컬럼을 기준으로 관련 범위만 스캔합니다. 그 결과 빅쿼리는 스캔량을 정확히 예측하지 못할 수도 있지만, 실제 실행 시 예상보다 줄어든 것을 확인할 수 있습니다.
최대 4개까지 클러스터링을 설정할 수 있는데 이 경우, 컬럼 순서는 빅쿼리가 데이터를 정렬하여 스토리지 블록으로 그룹화할 때, 순서대로 저장을 진행합니다.

클러스터링은 다음과 같은 상황에 사용하면 좋습니다.
- 필터링에서 자주 사용되는 컬럼
- 해당 컬럼의 값에 고유한 값이 많으면(카디널리티가 높음) 좋은 성능(쿼리 속도 향상, 스캔 비용 절감)을 보임
파티션 테이블과 클러스터링을 같이 사용하면 파티션으로 분할된 다음, 클러스터링 컬럼을 통해 각 파티션 내의 데이터를 클러스터링 합니다. 이러한 방법은 다음과 같은 상황에 사용하면 좋습니다.
- 엄격한 쿼리 비용 추정이 필요할 때
- 테이블 파티션을 나누면 평균 파티션 크기가 파티션당 최소 10GB일 때
- 작은 파티션을 여러 개 만들면 테이블의 메타데이터가 증가하여 쿼리할 때 메타데이터 액세스 시간에 영향을 줄 수 있음
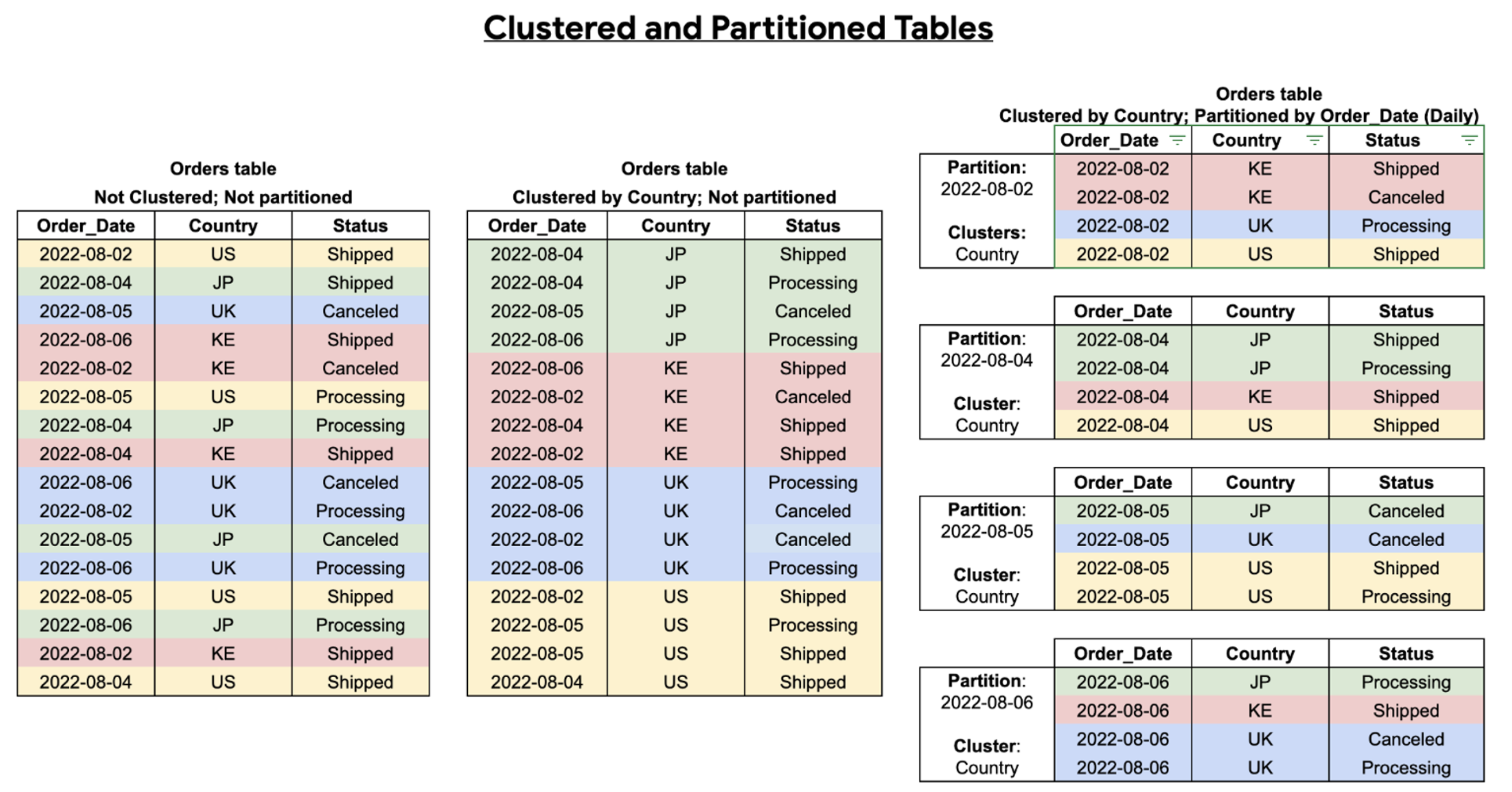
클러스터링된 테이블에 데이터가 추가되면 새 데이터가 블록으로 구성되고 새 스토리지 블록이 생성되거나 기존 블록이 업데이트될 수 있습니다. 새 데이터가 동일한 클러스터 값이 있는 기존 데이터와 그룹화되지 않을 수 있으므로 최적의 쿼리 및 스토리지 성능을 위해 블록 최적화가 필요한데 빅쿼리는 백그라운드에서 자동 재클러스터링을 수행합니다. 파티션을 나눈 테이블의 경우에는 각 파티션 범위 내의 데이터에 대해 클러스터링이 유지됩니다.
또한 빅쿼리는 limit 10 과 같이 조건을 추가해도 풀스캔을 진행하는데 클러스터링된 테이블에서는 데이터 읽기를 방지하는 모든 최적화를 수행합니다. 따라서 클러스터링된 테이블에선 limit 10을 수행하면 10행이 반환되는 즉시 실행 엔진이 데이터 읽기를 중지할 수 있습니다. 다만 쿼리 엔진이 여러 병렬 워커를 사용하는 방식으로 인해 어떤 최적화가 먼저 완료될 지 모르므로 검색되는 데이터의 양은 결정적이지 않습니다.

SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` LIMIT 1000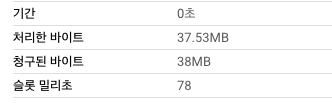
클러스터링에는 다음과 같은 제한사항이 있으므로 유의해야 합니다.
- 클러스터링은 최대 4개만 가능
- 클러스터링이 존재하지 않은 기존 테이블에 클러스터링을 적용할 경우, 기존 적재된 데이터는 클러스터링 되지 않고 새로 적재된 데이터만 클러스터링됨
- 기존 테이블을 삭제 후, 클러스터링된 테이블을 생성하고 데이터를 마이그레이션 해야 함
파티션된 필드와 동일하게 클러스터링된 컬럼을 제대로 적용하려면 복잡한 필터 표현식에 클러스터링된 컬럼을 사용하면 클러스터링이 적용되지 않습니다.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE CAST(customer_id AS STRING) = "10000"또한 클러스터링된 컬럼을 다른 컬럼(클러스터링된 컬럼 또는 클러스터링되지 않은 컬럼)과 비교할 경우, 클러스터링이 적용되지 않습니다.
SELECT SUM(totalSale) FROM `mydataset.ClusteredSalesData` WHERE customer_id = order_id[심화] - 클러스터링 키 사용하기
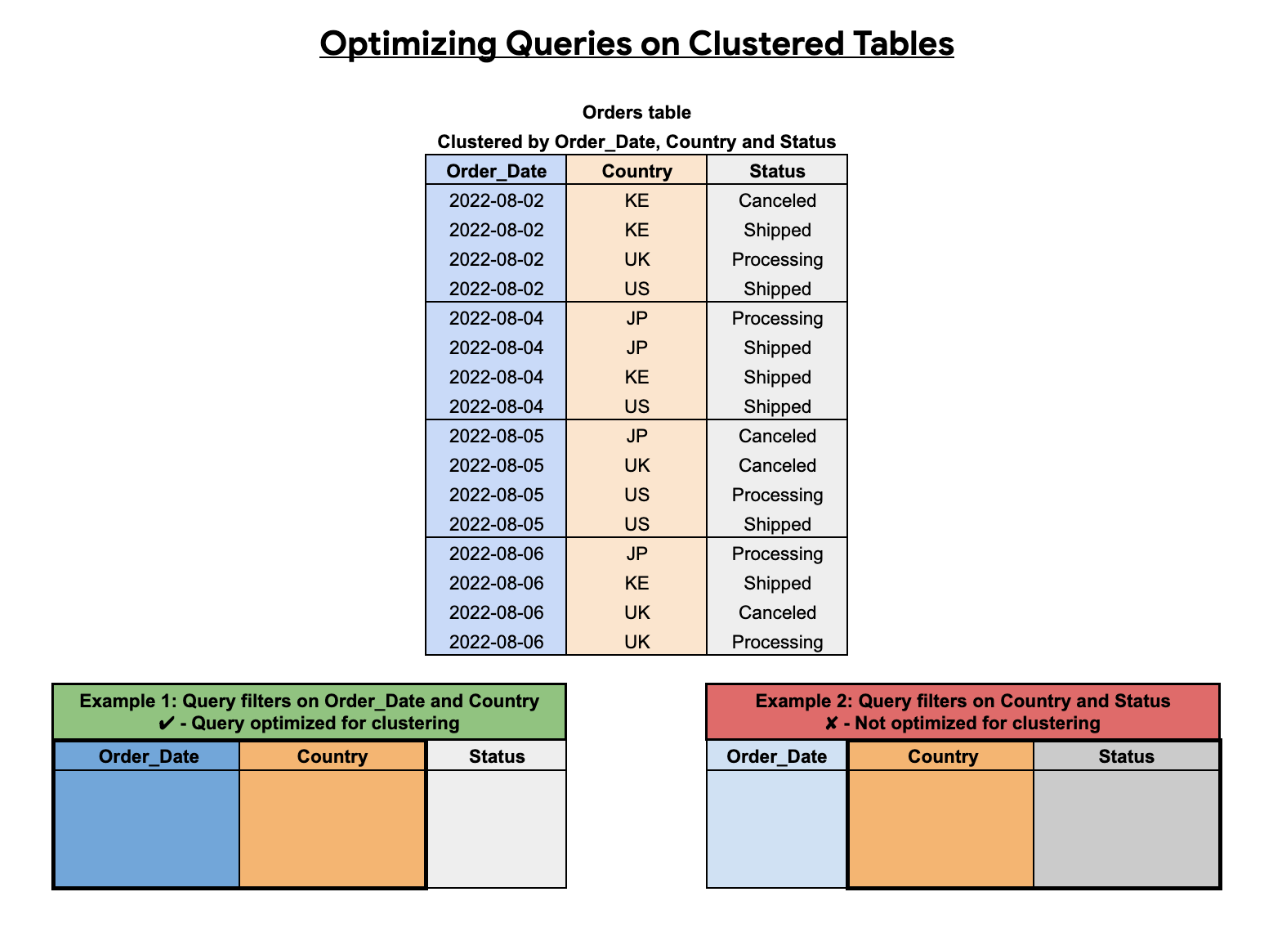
공식 문서에서는 클러스터링의 이점을 얻으려면 쿼리 필터 순서가 클러스터링된 컬럼 순서와 일치해야 하며 최소한 클러스터링된 첫 번째 컬럼이 포함되어야 한다고 나와있습니다.
- 공식 문서 예시
Order_Date,CountryStatus의 순서로 클러스터링이 되어 있는 테이블에서 및 를 필터링하는 쿼리는 클러스터링에 최적화되어 있지만 만 필터링하는 쿼리는 최적화되지 않습니다. 클러스터링 결과를 최적화하려면 첫 번째 클러스터링된 컬럼부터 순서대로 클러스터링된 컬럼을 필터링해야 합니다.
카디널리티가 높은순으로 클러스터링 테스트
그렇다면 실제로 위와 같은지 테스트를 진행해 봅니다. 테이블은 총 33기가 (약 3억건)의 데이터가 존재하고 클러스터링을 테스트할 컬럼은
first_, second_, third_이고 순서대로 고유 값의 수는 7,515,769, 24,230, 2개 입니다.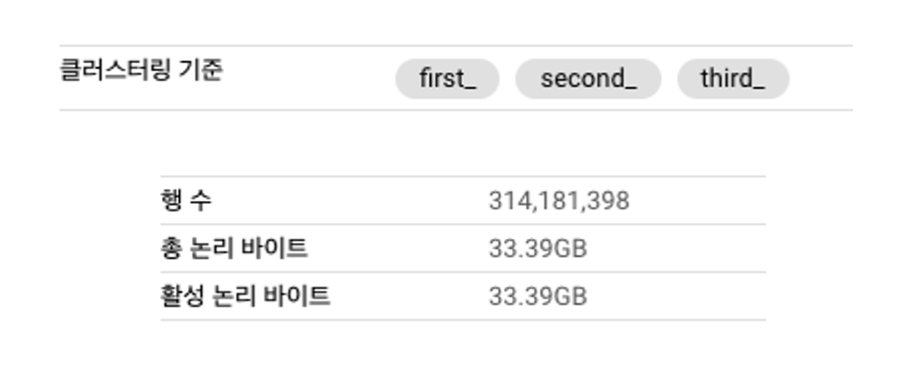
먼저
first_, second_, third_순으로 카디널리티가 높은 순(고유한 값이 많은 순 = 중복이 낮은 순)으로 클러스터링을 걸고 다음과 같이 조회를 해봅니다.SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_first` where first_ = 727577 and second_ = 11471 and third_ = 'F' -- 1건 출력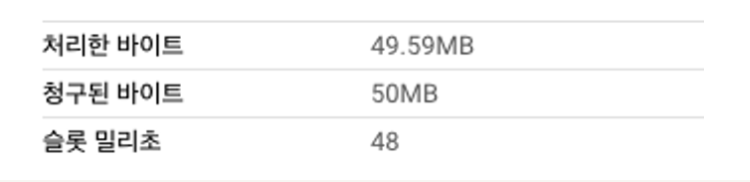
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_first` where first_ = 727577 and second_ = 11471 -- 1건 출력
third_필드를 생략해도 동일한 성능을 보여주는 것을 확인할 수 있습니다.다음을 순서를 반대로 필터를 한 결과입니다.
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_first` where third_ = 'F' and second_ = 11471 and first_ = 727577 -- 1건 출력
순서를 변경해도 크게 다르지 않은 것을 볼 수 있습니다.
다음은 필터에서
first_를 제거한 테스트입니다.SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_first` where second_ = 11471 and third_ = 'F' -- 158건 출력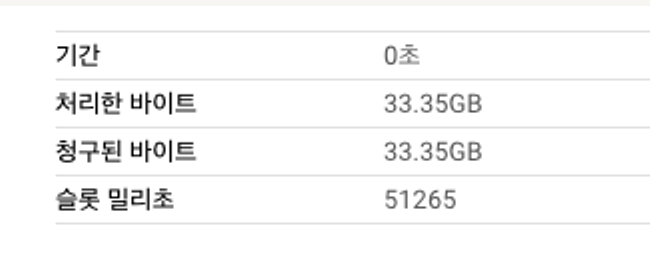
공식 문서가 이야기한 것처럼 클러스터링가 전혀 적용이 되지 않은 것을 볼 수 있습니다.
first_만 필터를 건다면 다음과 같습니다.SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_first` where first_ = 727577 -- 1091건 출력
카디널리티가 낮은순으로 클러스터링 테스트
위 테스트는 카디널리티가 높은 순으로 클러스터링을 적용했는데 이번엔 반대로 카디널리티가 낮은 순으로 적용하고 동일한 쿼리를 실행해 봅니다.
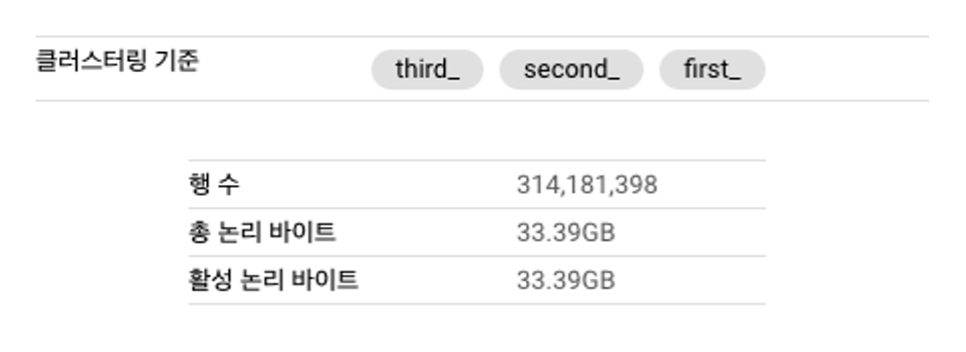
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where first_ = 727577 and second_ = 11471 and third_ = 'F' -- 1건 출력
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where first_ = 727577 and second_ = 11471 -- 1건 출력
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where third_ = 'F' and second_ = 11471 and first_ = 727577
카디널리티를 높은순으로 클러스터링을 추가한 테이블과 다르게 스캔량이나 슬롯 사용량이 늘어난 것을 볼 수 있습니다.
여기서 특이한 점은 클러스터링을 설정한 순으로(
third_, second_, first_) 필터 조건을 걸면 스캔량은 동일하지만 슬롯 사용은 현저히 줄어든 것을 볼 수 있습니다.이제
first_컬럼을 제거하고 테스트를 진행해 봅니다.SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where second_ = 11471 and third_ = 'F' -- 158건 출력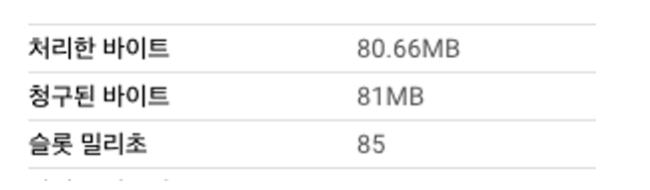
SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where third_ = 'F' and second_ = 11471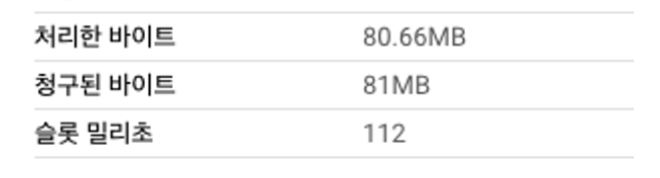
first_, second_, third_순으로 클러스터링을 걸었던 테스트에선first_를 제거하니 클러스터링이 적용이 안되었지만third_, second_, first_순으로 걸었던 이번 테스트에선 정상적으로 적용이 된 것을 확인할 수 있습니다.마지막으로
first_만 필터를 걸고 테스트를 해봅니다.SELECT * FROM `{프로젝트}.{데이터셋}.clustering_test_second` where first_ = 727577 -- 1091건 출력
결론
이러한 테스트를 통해 다음과 같은 점을 추측할 수 있었습니다.
first_, second_, third_순으로 클러스터링을 건다면 다음과 같이 정렬이 됩니다.first_ second_ third_ 1 라 B 2 다 A 3 나 A 3 라 B 4 가 B 5 마 A 6 나 B 7 다 B 8 가 A first_기반으로 그룹화 하여 정렬이 되고 그 다음,second_기반으로 그룹화 하여 정렬,third_기반으로 그룹화 하여 정렬 순으로 진행됩니다.카디널리티가 가장 높은 순이기 때문에
first_를 제외한 나머지second_와third_는 정렬이 제대로 이뤄지지 않은 것을 볼 수 있습니다.third_, second_, first_순으로 클러스터링을 건다면 다음과 같이 정렬이 될 것으로 추측합니다.third_ second_ first_ A 가 8 A 나 3 A 다 2 A 마 5 B 가 4 B 나 6 B 다 7 B 라 1 B 라 3 카디널리티가 낮은 순으로 정렬하면 보다 깔끔하게 정렬이 이뤄집니다. (추측)
first_, second_, third_순 정렬에선first_기반으로만 정렬이 이뤄져 있고 나머지second_와third_에선 정렬이 거의 이뤄지지 않아 필터 조건에first_컬럼이 빠지면 클러스터링이 적용이 되지 않은 것이고third_, second_, first_순 정렬에선 어느정도 정렬이 전부 이뤄져 있기 때문에first_를 필터에서 제거해도 클러스터링이 적용됩니다. 또한 필터에first_만 추가하여도 어느정도 정렬이 이뤄져 있기 때문에 약간이나마 클러스터링 효과를 볼 수 있습니다.요약
- 데이터가 큰 테이블은 샤딩보단 파티셔닝을 테이블에 적용
- 파티셔닝을 했는데도 데이터가 크다면 클러스터링을 적용
- 클러스터링이 걸려있는 테이블은 limit으로 비용 절감 효과가 있음
- 클러스터링 컬럼 적용 순서는 장단점이 있으므로 사용 정책에 따라 유연하게 적용
- 파티셔닝과 클러스터링은 제약조건이 있으므로 이를 잘 숙지하여 사용