-
루씬(Lucene)이란?LogSystem 2015. 11. 14. 21:18
1) 소개
루씬(Lucene)은 자바로 개발된 오픈소스 정보검색(IR, Information Retrieval) 라이브러리입니다. 루씬은 강력한 기능을 포함하고 간단해서 많은 IT업계에서 사용하고 있습니다.
루씬은 독립된 프로그램이 아닌 소프트웨어 라이브러리이기 때문에 루씬을 설치 후, 바로 검색서비스를 실행할 수 있는 것이 아닌, 사용자가 루씬 라이브러리를 사용해 검색서비스, 어플리케이션을 구현해야 합니다.
루씬을 사용할 때, 검색에 대한 전문적인 지식을 반드시 알 필요가 없고, 꼭 필요한 몇 가지 클래스들의 사용법만 익히면 색인과 검색 기능을 직접 추가할 수 있습니다.
2) Indexing과 검색이 적용 가능한 사례
이메일 검색: 저장된 메시지를 검색할 수 있고 새로 도착한 메시지를 색인에 추가할 수 있는 이메일 어플리케이션
온라인 문서 검색 : 온라인 문서 또는 저장된 출판물을 검색할 수 있는 CD기반이나 웹 기반 또는 어플리케이션에 포함된 문서 판독기
웹 페이지 검색 : 사용자가 방문한 모든 웹 페이지를 색인화하기 위해 개인 검색 엔진을 만들 수 있는 웹 브라우저 또는 프록시 서버
내용 검색 : 저장된 문서에서 특정 내용을 검색할 수 있는 애플리케이션
버전 관리 및 컨텐트 관리 : 문서나 문서 버전을 색인화해서 쉽게 검색할 수 있는 문서 관리 시스템
뉴스 및 유선(wire) 서비스 : 뉴스가 도착했을 때 기사를 색인할 수 있는 뉴스 서버나 릴레이 서버
> 각각에 대한 전용 라이브러리가 존재하는 것이 아닌, 루씬을 사용해 개발할 수 있는 영역입니다.
3) 루씬의 기능
색인을 저장할 수 있는 곳
RAMDirectory: 컴퓨터의 메인 메모리를 색인 장소로 사용
FSDirectory: 디스크의 파일 시스템에 색인을 저장 (가장 많이 사용)
JDBCDirectory: DB를 색인 저장소로 사용하는 방법. 일반적으로 지원하지는 않지만 별도의 루씬 샌드박스라는 것을 통해 지원
색인 기능 지원
검색 기능 지원
다양한 나라의 Full Text 분석기 지원 (한글 x)
Hadoop을 분산 파일 시스템으로 사용할 수 있음
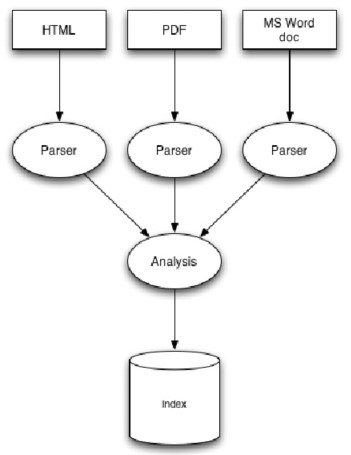
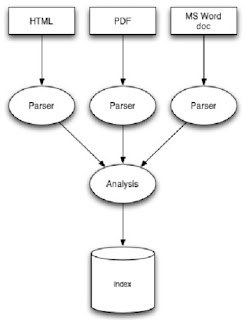
4) 해석(parse)의 필요성
실전에서는 단순한 문자열 색인보다 다양한 문서를 indexing하고 검색하는 작업이 빈번
XML, PDF, HTML, MS WORD와 같이 다양한 문서들을 색인화 하기 위해 각각의 문서를 루씬의 Analyzer가 이해할 수 있도록 해석(parse)해서 텍스트로 추출해 내는 과정이 필요
5) 결론
Full Text를 검색하는데 효율적
Full Text(Contents)와 text를 단어로 쪼개는 방법(Analyzer)을 제시하면 알아서 index를 구성해주고 빠른 검색 결과를 얻을 수 있다.