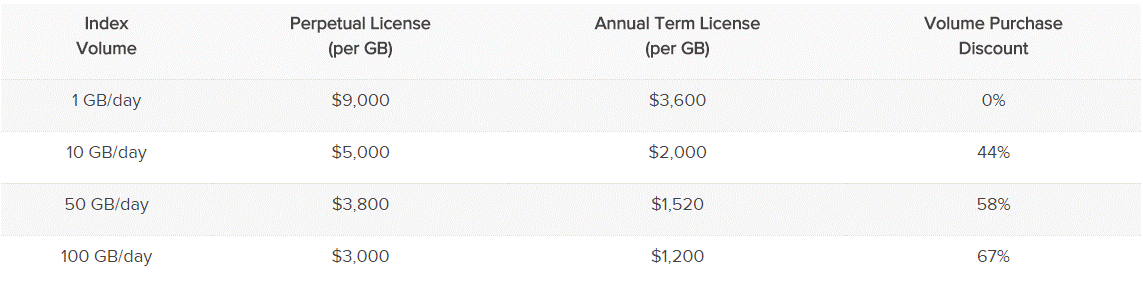-
스플렁크 개요
Splunk는 모든 머신 데이터를 실시간으로 collecting하고 Indexing하고 Reporting하는 End-to-End Solution. 모든 머신 데이터를 제한 없이 처리 할 수 있습니다. 사용자가 원하는 데이터를 즉시 분석할수 있으며, 원하는 Reporter, Dashboard를 추가적인 개발없이 구성 할 수 있습니다.
또한 통계적 명령들을 조합하여 여러가지 Query문으로 Search가 가능하며 Query문의 자동완성 기능까지 갖추고 있어 사용하기 매우 편리합니다. 하지만 상당히 높은 가격대가 높다는 단점이 있습니다.
특징
머신 데이터(machine data)를 강력한 통찰력으로 변환
모든 소스의 머신 데이터(machine data)를 실시간으로 수집하고 인덱싱합니다. 이를 통해 데이터를 검색, 모니터링, 분석 및 가상화하여 새로운 통찰력과 인텔리전스를 얻을 수 있습니다.
세부적인 가시성, 포렌식 및 문제 해결을 위한 정보 인덱싱
사용자와 사용자의 팀이 검색 결과를 공유
컴플라이언스 대응을 입증하기 위한 임시 보고서 생성
보안 사고, 서비스 레벨 및 기타 주요한 성능 메트릭 모니터링 위한 대화식 대시보드 생성
사용자 트랜잭션, 고객 행동, 시스템 작업, 보안 위협 및 부정행위 등 실시간 분석
데이터 인덱싱
로그, 클릭스트림 데이터, 구성, 센서 데이터, 트랩 및 경고, 변경 이벤트, 진단 명령 결과, API 및 메시지 대기열의 데이터, 사용자 지정 애플리케이션의 멀티라인 로그에 이르기까지 형식이나 위치에 관계없이 모든 머신 데이터(machine data)를 인덱싱합니다. 사전 정의된 스키마 없이 모든 소스, 형식 및 위치에서 데이터를 인덱싱할 수 있습니다. 그 인덱싱 결과를 문제 해결, 보안 사고 조사, 네트워크 모니터링, 컴플라이언스 보고, 비즈니스 분석 및 기타 중요한 용도로 사용할 수 있습니다.
검색 및 조사동일한 인터페이스를 사용하여 실시간 및 이력 데이터를 검색합니다. 유사한 검색 명령어를 사용하여 검색을 정의하거나 제한 또는 확장합니다. 또한 통계 보고 명령어를 사용하고, 트랜잭션 개수 업데이트, 매트릭 계산, 롤링 시간 윈도우 내에서 특정 조건을 찾을 수 있습니다. 검색 길잡이는 자동 완 성 및 상황별 도움말을 제공하므로 SPLTM(Search Processing Language)의 강력한 기능을 모두 활용할 수 있습니다.
검색 결과 활용
실시간으로 검색 결과를 활용할 수 있습니다. 결과의 타임라인을 줌인하거나 줌아웃하여 동향을 신속히 포착할 수 있습니다. 클릭만으로 결과를 즉시 볼 수 있고 불필요한 항목을 제거하여 방대한 데이터에서 필요한 정보를 얻을 수 있습니다. 예를 들면, 장애 접수 티켓에 대한 문제 해결, 보안 경고 발생과 관련된 조사 또는 단순한 데이터 검색 등 모든 상황에 대해 분 단위의 답변을 얻을 수 있습니다.
의미있는 데이터 구현
Splunk Enterprise는 자동으로 머신 데이터(machine data)에서 정보를 추출합니다. 필드 및 데이터 소스를 식별하고 이름 및 태그를 지정하여 더 많은 정보와 의미를 추가할 수 있습니다. 외부 자산 관리 데이터베이스 및 구성 관리 시스템과 사용자 디렉토리에서 얻은 정보를 추가할 수도 있습니다. 기본 머신 데이터(machine data)에서 관계를 설명하는 데이터 모델을 쉽게 정의하여 사용자가 검색 언어를 배우지 않고도 강력한 보고서를 작성할 수 있는 피벗 인터페이스를 제공합니다.
이벤트의 상관관계 추적
Splunk Enterprise 검색은 관련 없어 보이는 이벤트나 작업 간의 관계를 쉽게 설정하거나 찾을 수 있습니다. 시간, 외부 데이터, 위치, 하위 검색 또는 조인을 기반으로 머신 데이터(machine data)를 상관하고 관련 이벤트를 트랜잭션 또는 세션으로 식별합니다. 동향과 특성을 보고서 및 대시보드로 시각화합니다.
모니터링 및 경고
검색을 실시간 경고로 전환함으로써 이메일 또는 RSS를 통해 자동으로 통보하거나 교정 작업을 수행하고, SNMP 트랩을 시스템 관리 콘솔로 보내거나 서비스 데스크에 자동으로 티켓을 생성할 수 있습니다. 경고는 다양한 임계값, 동향 기반 조건 및 기타 복합 검색을 기준으로 발생시킬 수 있습니다. 경고 시 추가 정보를 확보하여 더 신속하게 근본 원인을 분석하고 문제를 해결할 수 있습니다.
보고 및 분석
조직의 모든 사용자가 신속하게 데이터를 분석할 수 있습니다. 보고서, 고급 그래프 및 차트를 작성하여 중요한 동향을 파악하고 고급 시각화를 생성해 주므로 이를 통해 빠른 통찰력을 제공받을 수 있습니다.
새로운 예측 시각화 : 최고점과 최저점을 예측하여 시스템 자원을 계획하거나 부하량 예측 가능
피벗 인터페이스 : 사용자가 검색 언어를 배우지 않고서도 머신 데이터(machine data) 조작 및 상호작용을 통해 풍부한 정보가 있는 강력한 보고서 작성
대시보드 통합 및 PDF 파일로 공유
가격
스플렁크 라이선스를 한번구입하면 추가비용 들지 않습니다. (유저, 검색, 변경, 리포트, 대시보드 의 양에 상관 X)

ELK 소개
ELK는 Elastic search, Log stash, Kibana의 약자입니다. 각각의 소개는 다음 링크에서 자세히 설명하고 있습니다.
- Elastic search
- Log stash
- Kibana
ELK는 다음과 같은 구조로 동작하고 있습니다.

차이점
Splunk와 ELK Stack은 End-to-End Solution이라는 면에서는 비슷할지 모르나, Splunk보다 기능적으로 부족합니다.
몇가지 예를 들자면 다음과 같다.
1. Splunk는 Query문의 자동완성 기능이 매우 잘되어있으나, Kibana는 이전에 사용했던 검색어에 대해서만 Query문의 자동완성을 지원 합니다.
2. Splunk는 한개의 그래프에 한개의 Query 결과가 붙는 형태인 반면, Kibana는 한개의 Dashboard에 한개의 Query가 붙는 형태로 이를 공유하여 사용하기 때문에 하나의 Dashboard가 다양한 데이터를 가지고 표현할 수가 없다.