-
데이터 모델링 기초 & 기법공부/데이터 2026. 4. 5. 00:08
1. 데이터 모델링 (Data Modeling)
1.1 정의 및 개요
데이터 모델링(Data Modeling)이란 조직의 데이터에 대한 구조화된 표현을 설계하는 과정입니다. 데이터 간의 관계(Relationships), 제약조건(Constraints), 패턴(Patterns)을 정의하여 비즈니스 요구사항을 데이터 구조로 변환합니다.
데이터 모델링이 중요한 이유는 다음과 같습니다:
- 데이터 품질 보장: 일관된 구조를 통해 데이터 무결성을 유지합니다
- 커뮤니케이션 도구: 비즈니스 이해관계자와 기술팀 간의 공통 언어를 제공합니다
- 성능 최적화: 쿼리 패턴에 맞는 구조 설계로 분석 속도를 향상시킵니다
- 규제 준수: GDPR, CCPA 등 데이터 규제 요구사항을 체계적으로 관리합니다
- 비용 관리: 잘못된 모델링은 Big-O 표기법으로 O(N)에서 O(N²)으로 비용이 기하급수적으로 증가할 수 있습니다
1.2 역사적 발전
데이터 모델링은 컴퓨팅의 발전과 함께 진화해왔습니다:
시대 주요 발전 핵심 기술/개념 1960s 초기 데이터 모델의 등장 계층형 모델(Hierarchical), 네트워크 모델(Network) 1970-80s 관계형 데이터베이스 혁명 관계형 DB(Relational DB), ERD(Entity-Relationship Diagram), Edgar Codd의 관계형 이론 1990s 데이터 웨어하우스의 탄생 Kimball의 차원 모델링, Inmon의 엔터프라이즈 DWH, Star/Snowflake Schema 2000s 빅데이터 시대 Hadoop, NoSQL, MapReduce, 스키마-온-리드(Schema-on-Read) 2010s 클라우드 및 현대 스택 클라우드 DWH(BigQuery, Snowflake, Redshift), Data Vault 2.0 2020s~현재 분산형 및 AI 시대 Data Mesh, Lakehouse, Semantic Layer, ML/AI 통합, 스트리밍 데이터 모델링 1.3 모델링 레벨
데이터 모델링은 추상화 수준에 따라 3개의 레벨로 구분됩니다:
개념적 모델 (Conceptual Model)
- 목적: 비즈니스 관점에서 "무엇을" 다루는지 정의
- 대상: 비즈니스 이해관계자, 경영진
- 내용: 핵심 엔티티와 관계만 표현 (예: "고객이 주문을 한다")
- 도구: 화이트보드, 다이어그램 도구
- 예시: 이커머스에서 "고객", "주문", "상품", "배송"이라는 핵심 개념과 이들의 관계를 정의
논리적 모델 (Logical Model)
- 목적: 데이터의 구조를 기술적으로 상세화
- 대상: 데이터 아키텍트, 분석가
- 내용: 엔티티의 속성, 데이터 타입, 기본키(PK)/외래키(FK), 정규화 수준 정의
- 도구: ERD 도구(ERwin, Lucidchart)
- 예시: 고객 테이블에 customer_id(PK), name(VARCHAR), email(VARCHAR), created_at(TIMESTAMP) 등 속성 정의
물리적 모델 (Physical Model)
- 목적: 실제 데이터베이스에 구현할 수 있는 수준으로 구체화
- 대상: 데이터 엔지니어, DBA
- 내용: 인덱스, 파티셔닝, 테이블스페이스, 스토리지 엔진 설정 등 포함
- 도구: DDL(Data Definition Language), 데이터베이스 관리 도구
- 예시: PostgreSQL에서 파티션 전략, 인덱스 타입(B-tree, GiST), 테이블 압축 설정 등 결정
1.4 접근 방법
Top-Down 접근 (하향식)
비즈니스 요구사항에서 출발하여 점진적으로 구체화하는 방식입니다.
- 프로세스: 비즈니스 요구사항 분석 → 개념적 모델 → 논리적 모델 → 물리적 모델
- 장점: 비즈니스 목표와 정렬된 일관성 있는 설계, 전체적인 데이터 거버넌스 확보
- 단점: 초기 설계에 시간이 오래 걸림, 모든 요구사항을 사전에 파악하기 어려움
- 적합 상황: 명확한 비즈니스 목표가 있고, 신규 시스템을 구축할 때
- 대표: Inmon 방법론
Bottom-Up 접근 (상향식)
기존 데이터 소스에서 출발하여 위로 작업하는 방식입니다.
- 프로세스: 기존 데이터 소스 분석 → 물리적 모델 → 논리적 모델 → 개념적 모델
- 장점: 빠른 구현, 기존 데이터 자산 활용, 점진적 확장
- 단점: 전체적인 일관성 부족 가능, 기존 데이터의 품질 문제 상속
- 적합 상황: 레거시 시스템 마이그레이션, 불완전한 요구사항, 빠른 프로토타이핑
- 대표: Kimball 방법론
혼합 접근 (Hybrid)
두 방법의 장점을 결합하는 실용적 접근입니다.
- 프로세스: 핵심 비즈니스 영역은 Top-Down으로, 세부 구현은 Bottom-Up으로 진행
- 장점: 전략적 방향성과 실용적 구현의 균형
- 적합 상황: 대부분의 실무 프로젝트에서 권장
1.5 주요 기법
차원 모델링 (Dimensional Modeling)
차원 모델링은 분석 쿼리에 최적화된 모델링 기법으로, 사실(Facts)과 차원(Dimensions)이라는 두 가지 핵심 개념으로 구성됩니다.
- 사실 테이블(Fact Table): 비즈니스 프로세스의 정량적 측정값을 저장합니다 (예: 매출액, 주문 수량, 클릭 수)
- 차원 테이블(Dimension Table): 사실에 대한 설명적 컨텍스트를 제공합니다 (예: 고객 정보, 상품 카테고리, 시간)
차원 모델링이 여전히 중요한 이유는 세분성(Granularity), 엔티티(Entity), 메트릭(Metric)에 대한 사전 고려를 강제하기 때문입니다.
Star Schema (스타 스키마)
Ralph Kimball이 제안한 대표적 차원 모델입니다.
- 구조: 중앙의 사실 테이블에 여러 차원 테이블이 직접 연결 (별 모양)
- 특징: 차원 테이블은 비정규화(Denormalized)되어 있어 조인이 단순
- 장점: 직관적 구조, 빠른 쿼리 성능, BI 도구와 높은 호환성
- 단점: 데이터 중복 발생, 차원 변경 시 넓은 영향 범위
- 적합: 비즈니스 인텔리전스, 셀프서비스 분석, 중소규모 데이터 웨어하우스
- 예시:
fact_sales테이블을 중심으로dim_customer,dim_product,dim_date,dim_store테이블이 연결

Star Schema 구조 다이어그램
[실무 예시 — 이커머스 매출 분석]
이커머스 플랫폼에서 "어떤 고객이, 언제, 어디서, 무엇을 얼마나 샀는가"를 분석하는 Star Schema입니다.
팩트 테이블 (fact_sales):
sale_key customer_key product_key date_key store_key quantity revenue 1001 301 501 20240315 201 2 59,800 1002 302 503 20240315 202 1 129,000 차원 테이블 예시 (dim_customer):
customer_key customer_id name city age_group loyalty_tier 301 C-001 김철수 서울 30대 Gold 302 C-002 이영희 부산 20대 Silver 분석 쿼리 예시:
-- 2024년 3월 서울 고객의 카테고리별 매출 SELECT dc.city, dp.category, SUM(fs.revenue) AS total_revenue FROM fact_sales fs JOIN dim_customer dc ON fs.customer_key = dc.customer_key JOIN dim_product dp ON fs.product_key = dp.product_key JOIN dim_date dd ON fs.date_key = dd.date_key WHERE dd.year = 2024 AND dd.month = 3 AND dc.city = '서울' GROUP BY dc.city, dp.category;Snowflake Schema (스노우플레이크 스키마)
Bill Inmon의 접근과 관련된 정규화된 차원 모델입니다.
- 구조: 차원 테이블이 정규화되어 하위 차원으로 분리 (눈송이 모양)
- 특징: 차원 테이블 간에도 계층적 관계 존재
- 장점: 데이터 중복 최소화, 복잡한 계층 구조 표현에 적합, 저장 공간 절약
- 단점: 조인이 많아져 쿼리 복잡도 증가, BI 도구 호환성 낮음
- 적합: 대규모 프로젝트, 복잡한 차원 계층이 있는 경우
- 예시:
dim_product→dim_category→dim_department로 계층 분리

Snowflake Schema 구조 다이어그램
[실무 예시 — 차원 정규화]
Star Schema의
dim_product하나를 세 테이블로 분리한 Snowflake 구조입니다.Star Schema (비정규화):
dim_product: product_key, product_name, category_name, department_name
→ 같은 카테고리의 모든 상품에 category_name이 중복 저장됨
Snowflake Schema (정규화):
테이블 컬럼 dim_product product_key, product_name, category_key dim_category category_key, category_name, department_key dim_department department_key, department_name 장단점 비교:
- "전자제품" 카테고리 이름 변경 시: Star → 수천 행 UPDATE / Snowflake → 1행 UPDATE
- 쿼리 시: Star → 조인 1회 / Snowflake → 조인 3회 (성능 저하)
Data Vault 모델링
Dan Linstedt가 고안한 모델로, 3NF와 Star Schema의 하이브리드 접근입니다.
구성 요소:
- Hub (허브): 비즈니스 키와 메타데이터를 저장 (예: 고객 ID, 상품 코드)
- Link (링크): 허브 간의 관계를 저장 (예: 고객-주문 관계)
- Satellite (새틀라이트): 시간에 따라 변하는 설명적 속성을 저장 (예: 고객 주소, 상품 가격)
장점:
- 새로운 데이터 소스를 빠르게 추가 가능 (허브/링크 추가)
- 완전한 이력 추적 (새틀라이트의 시간 기반 관리)
- 병렬 로드에 최적화
- 변화하는 비즈니스 환경에 유연하게 적응
단점:
- 높은 학습 곡선과 구현 복잡성
- 최종 사용자가 직접 쿼리하기 어려움 (Data Mart 레이어 필요)
- 성능 오버헤드 (조인 수 증가)
적합 상황: 대규모 데이터 통합 프로젝트, 거버넌드 데이터 레이크, 빠르게 변화하는 스키마 환경, 규제 산업에서 데이터 계보(Lineage) 추적이 필요한 경우

Data Vault Hub-Link-Satellite 구조 다이어그램
[실무 예시 — 금융 기관의 데이터 통합]
CRM, ERP, 모바일앱 3개 소스 시스템에서 고객-주문 데이터를 통합하는 Data Vault입니다.
Hub (비즈니스 키 저장):
hub_customer: customer_hk(PK), customer_id(BK), load_date, record_source
customer_hk customer_id load_date record_source a1b2c3 C-001 2024-01-01 CRM d4e5f6 C-001 2024-01-15 MobileApp Link (관계 저장):
link_order: order_hk, customer_hk, product_hk, load_date, record_source
Satellite (시간별 속성 변화 저장, append-only):
sat_customer_details: customer_hk, load_date, city, phone, record_source
customer_hk load_date city phone a1b2c3 2024-01-01 서울 010-1111 a1b2c3 2024-06-01 부산 010-1111 → 고객이 이사해도 기존 레코드를 수정하지 않고 새 행 추가 (완전한 감사 추적)
One Big Table (OBT)
모든 차원 정보를 하나의 넓은 비정규화 테이블에 포함시키는 극단적 비정규화 전략입니다.
- 구조: 사실 + 모든 차원 데이터를 단일 테이블에 통합
- 장점: 조인 불필요로 쿼리가 극히 단순, 최신 컬럼형 엔진(BigQuery, Snowflake)에서 뛰어난 성능
- 단점: 데이터 업데이트 시 매우 많은 행 수정 필요, 저장 공간 낭비, 데이터 불일치 위험
- 완화 전략: Apache Iceberg의 MERGE INTO 기능으로 업데이트 비용 완화 가능
- 적합: BI 대시보드용 최종 소비 레이어, 읽기 전용 분석 워크로드
[실무 예시 — BI 대시보드용 OBT]
Star Schema의 fact_sales + 4개 차원을 사전에 조인하여 단일 와이드 테이블로 만든 예시입니다.
Star Schema → OBT 변환:
-- OBT 생성 CREATE TABLE obt_sales AS SELECT fs.sale_key, fs.quantity, fs.revenue, -- 고객 차원 (dim_customer 조인) dc.customer_id, dc.name AS customer_name, dc.city, dc.age_group, dc.loyalty_tier, -- 상품 차원 (dim_product 조인) dp.product_name, dp.category, dp.brand, -- 날짜 차원 (dim_date 조인) dd.year, dd.month, dd.quarter, dd.day_of_week, -- 매장 차원 (dim_store 조인) ds.store_name, ds.region FROM fact_sales fs JOIN dim_customer dc ON fs.customer_key = dc.customer_key JOIN dim_product dp ON fs.product_key = dp.product_key JOIN dim_date dd ON fs.date_key = dd.date_key JOIN dim_store ds ON fs.store_key = ds.store_key;이후 분석가는 복잡한 조인 없이
SELECT region, SUM(revenue) FROM obt_sales GROUP BY region만으로 바로 분석합니다.트레이드오프: 저장 공간 약 3배 증가 vs 조인 제거로 쿼리 속도 10~45% 향상
기타 기법
3NF (Third Normal Form, 제3정규형)
- 데이터 중복을 최소화하고 무결성을 보장하는 정규화 기법
- OLTP(트랜잭션 처리) 시스템에 최적
- 쓰기 성능에 유리하나, 분석 쿼리에서는 과도한 조인 발생
[실무 예시 — 주문 시스템 정규화 과정]
정규화 전 (비정규화 테이블 — 중복과 이상현상 발생):
order_id customer_id customer_name customer_city product_id product_name category quantity price O-001 C-001 김철수 서울 P-101 노트북 전자제품 1 1,200,000 O-002 C-001 김철수 서울 P-102 마우스 전자제품 2 30,000 → "서울" 오타 수정 시 고객 C-001의 모든 주문 행을 UPDATE해야 함 (갱신 이상)
정규화 후 (3NF — 각 정보를 한 곳에만 저장):
-- 고객 테이블 CREATE TABLE customers ( customer_id VARCHAR PRIMARY KEY, customer_name VARCHAR, customer_city VARCHAR ); -- 상품 테이블 CREATE TABLE products ( product_id VARCHAR PRIMARY KEY, product_name VARCHAR, category VARCHAR, price DECIMAL ); -- 주문 테이블 (FK로 참조) CREATE TABLE orders ( order_id VARCHAR PRIMARY KEY, customer_id VARCHAR REFERENCES customers(customer_id), product_id VARCHAR REFERENCES products(product_id), quantity INT );→ 고객 도시 변경 시
customers테이블 1행만 UPDATE
데이터베이스 정규화 갱신 이상현상
Anchor Modeling (앵커 모델링)
- 각 속성을 별도의 테이블로 저장하는 극도로 유연한 접근
- 구성: Anchors(식별자) + Attributes(속성) + Ties(관계) + Knots(유한 도메인)
- 스키마 진화(Schema Evolution)에 매우 강하며 데이터 중복 최소화
- 다만, 쿼리 시 수많은 조인이 필요하여 성능에 유의해야 합니다
[실무 예시 — 직원 인사 정보 관리]
직원의 이름, 부서, 급여가 각각 독립적으로 변화할 때, Anchor Modeling은 각 속성을 별도 테이블로 분리합니다.
일반 방식 (단일 테이블):
-- 부서 변경 시 전체 행 복사 필요 employee: emp_id, name, department, salary, valid_from, valid_toAnchor Modeling:
-- Anchor: 직원 식별자만 Employee(emp_id, emp_load_date) -- Attribute: 각 속성이 별도 테이블로 이력 관리 Employee_Name(emp_id, name, valid_from, valid_to) Employee_Department(emp_id, department, valid_from, valid_to) Employee_Salary(emp_id, salary, valid_from, valid_to)→ 부서만 변경될 때
Employee_Department에만 새 행 추가 (이름, 급여 테이블은 무관)→ 스키마에 "직급" 속성 추가 시
Employee_Grade테이블만 추가 (기존 테이블 수정 없음)
Anchor Modeling 개념 다이어그램
Bitemporal Modeling (이중 시간 모델링)
- 2개의 타임라인을 동시에 추적: 비즈니스 시간(Business Time) + 시스템 시간(System Time)
- 비즈니스 시간: 현실 세계에서 사건이 발생한 시점
- 시스템 시간: 데이터베이스에 정보가 기록/수정된 시점
- 용도: 금융 보고, 감사 추적, 데이터 수정 이력 관리
- SQL:2011 표준에서 공식 지원
[실무 예시 — 금융 계좌 잔액의 이중 시간 추적]
2024년 3월 31일에 "2024년 1월의 잔액이 실제로는 500만원이었다"는 수정 사항이 발생한 경우:
단일 시간 (SCD Type 2만 사용) — 한계:
- 수정 이전 기록이 사라져 "3월 31일 이전에는 1월 잔액을 어떻게 알고 있었는가?"를 알 수 없음
Bitemporal 테이블:
account_id balance valid_from valid_to recorded_from recorded_to ACC-001 3,000,000 2024-01-01 2024-01-31 2024-01-01 2024-03-31 ACC-001 5,000,000 2024-01-01 2024-01-31 2024-03-31 9999-12-31 - valid_from/to: 현실 세계에서 해당 잔액이 유효했던 기간 - recorded_from/to: 데이터베이스에 이 정보가 기록되어 있었던 기간 쿼리 예시:
-- "3월 15일 시점에 알고 있던 1월 잔액은?" (규제 감사용) SELECT balance FROM account_history WHERE account_id = 'ACC-001' AND '2024-01-15' BETWEEN valid_from AND valid_to AND '2024-03-15' BETWEEN recorded_from AND recorded_to; -- 결과: 3,000,000 (수정 전 알고 있던 값)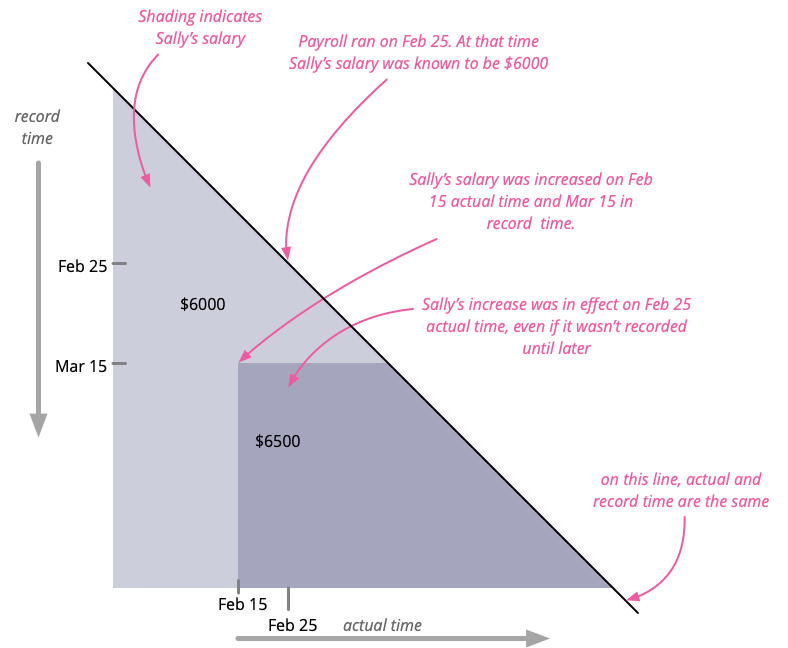
Bitemporal Modeling 두 타임라인 다이어그램
Entity-Centric Data Modeling (엔티티 중심 모델링, ECM)
- 핵심 비즈니스 엔티티(사용자, 고객, 제품, 캠페인)를 분석의 최우선 대상으로 설정
- 차원 모델링과 ML 피처 엔지니어링(Feature Engineering)을 통합하는 현대적 접근
- ML 파이프라인에서 엔티티별 피처 테이블을 구축할 때 유용
[실무 예시 — 고객 엔티티 중심 분석]
전통적 Star Schema는 "주문 이벤트" 중심이지만, ECM은 "고객" 엔티티를 중심에 두고 관련 메트릭과 속성을 모두 포함합니다.
전통적 Star Schema 분석 방식:
-- 고객별 총 매출 계산 (복잡한 조인 필요) SELECT dc.customer_id, dc.city, SUM(fs.revenue) AS total_revenue, COUNT(DISTINCT fs.sale_key) AS order_count, AVG(fs.revenue) AS avg_order_value FROM fact_sales fs JOIN dim_customer dc ON fs.customer_key = dc.customer_key GROUP BY dc.customer_id, dc.city;ECM 방식 — 고객 엔티티 테이블 (핵심 속성 + 메트릭 사전 계산):
-- entity_customer: 고객 엔티티에 핵심 메트릭을 포함 CREATE TABLE entity_customer AS SELECT customer_id, city, age_group, loyalty_tier, SUM(CASE WHEN sale_date >= CURRENT_DATE - 30 THEN revenue ELSE 0 END) AS revenue_last_30d, SUM(CASE WHEN sale_date >= CURRENT_DATE - 90 THEN revenue ELSE 0 END) AS revenue_last_90d, COUNT(DISTINCT CASE WHEN sale_date >= CURRENT_DATE - 30 THEN order_id END) AS orders_last_30d, MIN(sale_date) AS first_purchase_date, MAX(sale_date) AS last_purchase_date, DATEDIFF(CURRENT_DATE, MAX(sale_date)) AS days_since_last_purchase FROM customers c LEFT JOIN sales s ON c.customer_id = s.customer_id GROUP BY customer_id, city, age_group, loyalty_tier;활용:
- BI 분석:
SELECT city, AVG(revenue_last_90d) FROM entity_customer GROUP BY city - ML 모델: 이탈 예측 모델의 피처로
days_since_last_purchase,orders_last_30d등 직접 활용 - 메트릭 일관성: "활성 고객" 정의를 한 곳에서 관리
Galaxy Schema (Fact Constellation)
정의: 여러 Fact Table이 Conformed Dimension을 공유하는 구조입니다. Star Schema의 확장형으로, 복수의 Star Schema가 공유 차원을 통해 연결된 형태입니다.
구조 예시 (이커머스):
fact_sales와fact_inventory가dim_product,dim_date를 공유합니다fact_returns도dim_customer,dim_product,dim_date를 공유합니다
-- fact_sales: 판매 이벤트 fact_sales(sale_key, date_key, customer_key, product_key, store_key, quantity, revenue) -- fact_inventory: 재고 스냅샷 (고객 차원 없음) fact_inventory(snapshot_key, date_key, product_key, store_key, quantity_on_hand) -- 공유 차원 dim_product(product_key, product_name, category, brand) dim_date(date_key, date, year, month, quarter)장점:
- 여러 비즈니스 프로세스를 통합 분석할 수 있습니다
- Conformed Dimension을 재사용하여 일관성을 확보합니다
단점:
- 복잡도가 증가합니다
- 설계 전 Bus Matrix 작성이 필수적입니다
적합 상황: 성숙한 DWH 환경, 다수 비즈니스 프로세스를 통합해야 하는 경우
1.6 Fact Table 3가지 유형
Fact Table은 저장하는 데이터의 성격에 따라 3가지 유형으로 분류됩니다. 각 유형은 세분성(Grain), 행 생성/수정 패턴, 적합한 분석 시나리오가 다릅니다.
① Transactional Fact Table (트랜잭션 팩트 테이블)
비즈니스 이벤트 1건당 1행을 저장합니다. 가장 세밀한 세분성을 가집니다.
- 예시: 주문 1건, 결제 1건, 클릭 1회
- 특징: 대용량이며, 행 추가만 발생합니다 (UPDATE 없음)
- 사용 사례: 이커머스 주문, 클릭스트림 분석
-- fact_sales: 트랜잭션 팩트 테이블 -- 한 행 = 하나의 판매 이벤트 fact_sales: sale_key -- PK date_key -- FK → dim_date customer_key -- FK → dim_customer product_key -- FK → dim_product store_key -- FK → dim_store quantity INT unit_price DECIMAL revenue DECIMAL② Periodic Snapshot Fact Table (주기적 스냅샷 팩트 테이블)
정해진 주기마다 상태를 저장합니다. 이벤트가 없어도 행이 존재합니다 (0 저장).
- 예시: 매일 자정 계좌 잔액, 매주 재고 수량
- 특징: 기간 내 상태 변화가 없어도 레코드가 생성됩니다
- 사용 사례: 재고 관리, 계좌 잔액, KPI 모니터링
-- fact_inventory_daily: 주기적 스냅샷 팩트 테이블 -- 한 행 = 특정 날짜의 특정 상품·매장 재고 상태 fact_inventory_daily: snapshot_key -- PK date_key -- FK → dim_date product_key -- FK → dim_product store_key -- FK → dim_store quantity_on_hand INT reorder_point INT③ Accumulating Snapshot Fact Table (누적 스냅샷 팩트 테이블)
비즈니스 프로세스의 생애주기를 1행으로 추적하며, 단계별로 업데이트합니다.
- 예시: 주문 접수 → 결제 → 출고 → 배송 → 완료를 1행으로 관리
- 특징: 여러 날짜 컬럼을 포함하며, 단계 완료 시 해당 컬럼이 업데이트됩니다
- 사용 사례: 주문처리 파이프라인, 대출 심사, 채용 프로세스
-- fact_order_fulfillment: 누적 스냅샷 팩트 테이블 -- 한 행 = 하나의 주문 전체 생애주기 fact_order_fulfillment: order_key -- PK order_date_key -- 주문 접수일 payment_date_key -- 결제 완료일 (NULL → 완료 시 업데이트) shipment_date_key -- 출고일 delivery_date_key -- 배송 완료일 days_to_payment INT -- 계산된 지연 지표 days_to_delivery INTFact Table 유형 비교
유형 세분성 행 생성 행 수정 대표 사용 사례 Transactional 가장 세밀 이벤트 발생 시 없음 주문, 클릭, 결제 Periodic Snapshot 주기적 주기마다 없음 재고, 잔액, KPI Accumulating Snapshot 프로세스 단위 프로세스 시작 시 단계 완료 시 주문처리, 대출심사
1.7 Conformed Dimensions (일치된 차원)
정의
Conformed Dimensions(일치된 차원)이란 여러 Fact Table과 Data Mart에서 동일한 정의와 내용으로 공유되는 Dimension 테이블입니다. Kimball Bus Architecture의 핵심 개념입니다.
Bus Matrix 예시 (이커머스)
비즈니스 프로세스 dim_date dim_customer dim_product dim_store fact_sales O O O O fact_inventory O - O O fact_returns O O O O fact_web_events O O O - →
dim_date,dim_product은 모든 Fact에서 공유 → Conformed Dimension"Drill Across" 분석
Conformed Dimension을 통해 서로 다른 Fact Table의 데이터를 통합 분석할 수 있습니다. 이를 "Drill Across"라고 합니다.
-- Sales와 Inventory를 같은 날짜·상품 기준으로 통합 분석 SELECT d.date, p.product_name, s.total_revenue, i.avg_inventory FROM dim_date d JOIN ( SELECT date_key, product_key, SUM(revenue) AS total_revenue FROM fact_sales GROUP BY 1, 2 ) s ON d.date_key = s.date_key JOIN ( SELECT date_key, product_key, AVG(quantity_on_hand) AS avg_inventory FROM fact_inventory GROUP BY 1, 2 ) i ON d.date_key = i.date_key AND s.product_key = i.product_key JOIN dim_product p ON s.product_key = p.product_key;구현 원칙
- 비즈니스 키(Natural Key) 기준 일관성 유지: 모든 Data Mart에서 동일한 비즈니스 키를 사용합니다
- 변경 시 모든 Data Mart에 동시 반영: 차원 데이터의 변경은 모든 관련 마트에 전파됩니다
- 중앙 차원 관리팀이 소유권 보유: Conformed Dimension의 정의와 변경은 중앙에서 통제합니다
1.8 Activity Schema
정의
Activity Schema는 모든 데이터를 Entity(엔티티)가 수행한 Activity(활동) 스트림으로 모델링하는 접근입니다. Maxime Beauchemin이 제안한 방식입니다.
핵심 구성
-- Activity Stream 테이블 구조 activity_stream: ts TIMESTAMP -- 이벤트 발생 시각 activity_type VARCHAR -- 이벤트 유형 entity_id VARCHAR -- 주체 (customer_id 등) feature_1 VARCHAR -- 추가 속성 feature_2 VARCHAR revenue DECIMAL예시 데이터
ts activity_type entity_id feature_1 revenue 2024-03-15 10:00 viewed_product C-001 P-101 NULL 2024-03-15 10:05 added_to_cart C-001 P-101 NULL 2024-03-15 10:10 completed_order C-001 P-101 59,800 장점
- 새 이벤트 타입 추가 시 스키마 변경이 필요 없습니다
- 행동 분석에 자연스러운 구조입니다
단점
- 집계 쿼리가 복잡합니다
- BI 도구 호환성이 낮습니다
적합 상황
- SaaS 제품 분석
- 고객 여정(Customer Journey) 분석
- 앱 행동 분석
1.9 데이터 모델링 안티패턴
실무에서 자주 발생하는 7가지 데이터 모델링 실수와 올바른 접근 방법을 정리합니다.
① EAV 패턴 남용
attribute_name/attribute_value 형태로 속성을 행으로 저장하는 패턴입니다. 쿼리가 극도로 복잡해집니다.
잘못된 예시 (EAV):
-- EAV: 속성을 행으로 저장 CREATE TABLE product_attributes ( product_id VARCHAR, attr_name VARCHAR, -- 'color', 'size', 'weight' ... attr_value VARCHAR -- 모든 값이 문자열로 저장됨 ); -- 상품의 색상과 사이즈를 조회하려면 PIVOT 필요 SELECT product_id, MAX(CASE WHEN attr_name = 'color' THEN attr_value END) AS color, MAX(CASE WHEN attr_name = 'size' THEN attr_value END) AS size FROM product_attributes GROUP BY product_id; -- 속성이 늘어날수록 CASE문이 무한히 증가올바른 예시 (명시적 컬럼):
-- 속성을 컬럼으로 명시 CREATE TABLE products ( product_id VARCHAR PRIMARY KEY, color VARCHAR, size VARCHAR, weight DECIMAL ); -- 단순 조회 SELECT product_id, color, size FROM products;② 과도한 정규화
분석 쿼리에 조인이 수십 개 발생하여 성능이 저하됩니다.
잘못된 예시 (과도한 정규화):
-- 주소를 5개 테이블로 분리 SELECT c.name, a.street, ci.city_name, s.state_name, co.country_name FROM customers c JOIN addresses a ON c.address_id = a.address_id JOIN cities ci ON a.city_id = ci.city_id JOIN states s ON ci.state_id = s.state_id JOIN countries co ON s.country_id = co.country_id; -- 단순 주소 조회에 4번 조인올바른 예시 (분석 환경에 적합한 비정규화):
-- 분석용 차원 테이블에서는 적절히 비정규화 CREATE TABLE dim_customer ( customer_key INT PRIMARY KEY, customer_name VARCHAR, street VARCHAR, city VARCHAR, state VARCHAR, country VARCHAR ); -- 조인 없이 바로 조회 SELECT customer_name, city, country FROM dim_customer;③ NULL 의미 혼용
"모름" / "없음" / "해당없음"을 모두 NULL로 처리하여 분석 시 혼란을 야기합니다.
잘못된 예시 (NULL 혼용):
-- NULL이 3가지 의미를 동시에 가짐 SELECT * FROM dim_customer WHERE phone IS NULL; -- 결과: 전화번호를 모르는 고객? 전화가 없는 고객? 수집 거부 고객?올바른 예시 (의미 구분):
CREATE TABLE dim_customer ( customer_id VARCHAR PRIMARY KEY, phone VARCHAR, phone_status VARCHAR -- 'known', 'unknown', 'not_applicable', 'refused' ); -- 명확한 필터링 SELECT * FROM dim_customer WHERE phone_status = 'unknown';④ 비즈니스 로직 ETL 하드코딩
규칙 변경 시 ETL 전체를 수정해야 합니다.
잘못된 예시 (하드코딩):
-- ETL 파이프라인 내부에 비즈니스 규칙 하드코딩 INSERT INTO mart_sales SELECT *, CASE WHEN revenue >= 1000000 THEN 'VIP' WHEN revenue >= 500000 THEN 'Gold' ELSE 'Standard' END AS customer_tier -- 기준 변경 시 ETL 코드 수정 필요 FROM staging_sales;올바른 예시 (규칙 테이블 분리):
-- 비즈니스 규칙을 별도 테이블로 관리 CREATE TABLE tier_rules ( tier_name VARCHAR, min_revenue DECIMAL, max_revenue DECIMAL, effective_from DATE, effective_to DATE ); -- ETL에서 규칙 테이블을 참조 INSERT INTO mart_sales SELECT s.*, t.tier_name AS customer_tier FROM staging_sales s JOIN tier_rules t ON s.revenue BETWEEN t.min_revenue AND t.max_revenue AND CURRENT_DATE BETWEEN t.effective_from AND t.effective_to;⑤ Grain 미정의
Fact Table에 서로 다른 세분성이 혼재하여 집계 결과가 부정확해집니다.
잘못된 예시 (Grain 혼재):
-- 하나의 Fact Table에 주문 행과 일별 요약 행이 혼재 -- 행 1: sale_key=1001, date_key=20240315, revenue=59800 (개별 주문) -- 행 2: sale_key=NULL, date_key=20240315, revenue=1500000 (일별 합계) -- SUM(revenue)를 하면 이중 집계 발생!올바른 예시 (Grain 명확화):
-- 트랜잭션 레벨 Fact (Grain: 주문 1건당 1행) CREATE TABLE fact_sales ( sale_key INT PRIMARY KEY, date_key INT, customer_key INT, product_key INT, revenue DECIMAL ); -- 집계 테이블은 별도로 분리 (Grain: 일별 1행) CREATE TABLE fact_sales_daily_summary ( date_key INT PRIMARY KEY, total_revenue DECIMAL, total_orders INT );⑥ Surrogate Key 없는 SCD Type 2
Natural Key만으로는 시점을 특정할 수 없습니다.
잘못된 예시 (Natural Key만 사용):
-- Natural Key만으로는 어떤 버전인지 특정 불가 SELECT * FROM dim_customer WHERE customer_id = 'C-001'; -- 결과: 2행 반환 (서울 버전, 부산 버전) → Fact와 조인 시 중복 발생 -- Fact 테이블 조인 시 SELECT f.revenue, d.city FROM fact_sales f JOIN dim_customer d ON f.customer_id = d.customer_id; -- customer_id가 2행이므로 매출이 2배로 뻥튀기!올바른 예시 (Surrogate Key 사용):
-- Surrogate Key로 각 버전을 고유하게 식별 CREATE TABLE dim_customer ( customer_key INT PRIMARY KEY, -- Surrogate Key customer_id VARCHAR, -- Natural Key city VARCHAR, effective_start DATE, effective_end DATE, is_current CHAR(1) ); -- Fact 테이블은 Surrogate Key로 정확한 시점의 차원 참조 SELECT f.revenue, d.city FROM fact_sales f JOIN dim_customer d ON f.customer_key = d.customer_key; -- 1:1 조인으로 정확한 결과⑦ 데이터 레이어 스킵
Raw에서 직접 비즈니스 로직을 적용하여 재처리가 불가능해집니다.
잘못된 예시 (레이어 스킵):
-- Raw 데이터에서 바로 비즈니스 로직 적용 CREATE TABLE mart_sales AS SELECT raw.order_id, UPPER(TRIM(raw.customer_name)) AS customer_name, -- 정제 + 비즈니스 로직 혼재 raw.amount * 1.1 AS revenue_with_tax, -- 세금 계산 하드코딩 CASE WHEN raw.status = 'C' THEN 'Completed' END AS status -- 코드 매핑 FROM raw_orders raw; -- 세율 변경 시? raw부터 전체 재처리 필요올바른 예시 (레이어 분리):
-- 1단계: Staging (정제만) CREATE TABLE stg_orders AS SELECT order_id, UPPER(TRIM(customer_name)) AS customer_name, amount, status FROM raw_orders; -- 2단계: Core (비즈니스 규칙 적용) CREATE TABLE core_orders AS SELECT o.order_id, o.customer_name, o.amount * t.tax_rate AS revenue_with_tax, sm.status_label AS status FROM stg_orders o JOIN tax_rates t ON t.effective_date = CURRENT_DATE JOIN status_mapping sm ON o.status = sm.status_code; -- 세율 변경 시 core_orders만 재처리 (raw, stg 불필요)