-
[Spark] 카탈리스크 옵티마이저공부 2026. 4. 27. 02:09
1. 개요
Apache Spark의 쿼리 실행 성능을 결정하는 핵심 엔진이 바로 카탈리스트 옵티마이저(Catalyst Optimizer)입니다. Spark SQL은 사용자가 작성한 SQL 쿼리나 DataFrame/Dataset API 코드를 내부적으로 최적의 실행 계획으로 변환하는데, 이 과정 전체를 카탈리스트 옵티마이저가 담당합니다.
카탈리스트 옵티마이저는 Spark 1.3(2014년)에 처음 도입되었으며, Scala의 함수형 프로그래밍 특성을 적극 활용하여 확장 가능한 구조로 설계되었습니다. 규칙 기반(Rule-Based) 최적화와 비용 기반(Cost-Based) 최적화를 모두 지원하며, Parquet·Hive·JDBC 등 다양한 데이터 소스와의 통합도 지원합니다.
사용자는 "무엇을(What)" 쿼리할지만 기술하면 되고, "어떻게(How)" 실행할지는 카탈리스트가 자동으로 결정합니다.
Catalyst Optimizer 4단계 파이프라인 개요 (출처: Databricks)
2. 카탈리스트 옵티마이저 동작 원리
2.1 핵심 개념: 트리 변환 (Tree Transformation)
카탈리스트 내부는 모든 쿼리 표현을 트리(Tree) 구조로 표현합니다. 모든 노드는 불변(Immutable) 객체이며, 최적화는 이 트리에 변환 규칙을 반복 적용하는 방식으로 이루어집니다.
기본 노드 유형:
Literal(value)— 상수값Attribute(name)— 입력 행의 속성(컬럼)Add(left, right)— 두 표현식의 합
변환 규칙 예시:
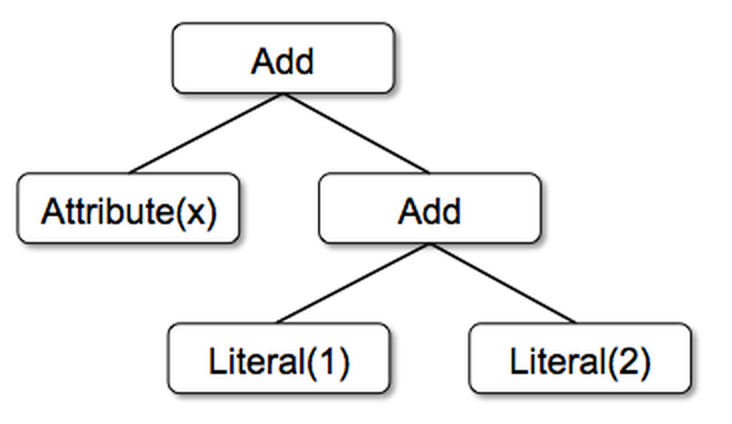
tree.transform { case Add(Literal(c1), Literal(c2)) => Literal(c1 + c2) case Add(left, Literal(0)) => left }트리 변환 전/후 시각화 (x + 1 + 2 예시):
변환 전: 변환 후: Add Add / \ → / \ Add Lit(2) x(Attr) Lit(3) / \ x(Attr) Lit(1) → Add(Lit(1), Lit(2)) = Lit(3) 으로 상수 폴딩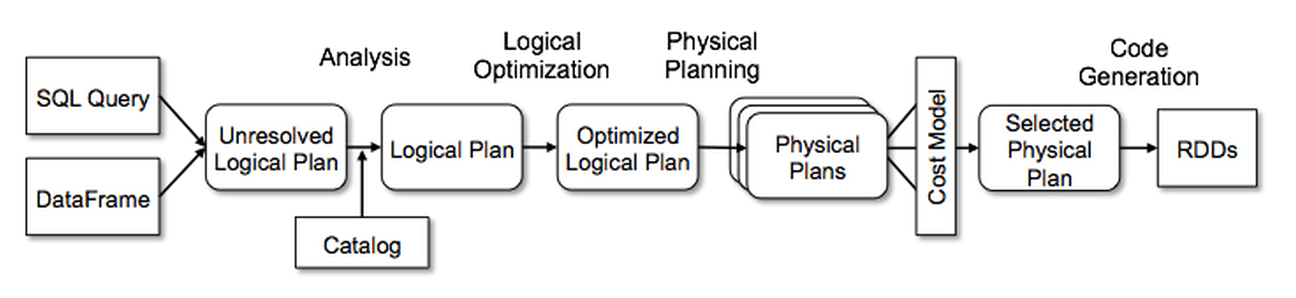
Catalyst 트리 변환 다이어그램 (출처: Databricks)
규칙들은 배치(Batch)로 묶여 트리에 변화가 없을 때까지 반복(고정점, Fixed-Point) 실행됩니다. Spark 2.4.7 기준 25개 배치, 109개 규칙(고유 69개)이 존재합니다.
2.2 4단계 파이프라인
SQL / DataFrame API ↓ ┌──────────────────────────────────────────────────┐ │ 1. Analysis │ │ Unresolved Logical Plan → Analyzed LP │ │ (컬럼명·타입 해석, Catalog 조회) │ └───────────────────┬──────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────┐ │ 2. Logical Optimization │ │ Analyzed LP → Optimized LP │ │ (Predicate Pushdown, Constant Folding 등) │ └───────────────────┬──────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────┐ │ 3. Physical Planning │ │ Optimized LP → SparkPlan │ │ (BroadcastHashJoin vs SortMergeJoin 선택) │ └───────────────────┬──────────────────────────────┘ ↓ ┌──────────────────────────────────────────────────┐ │ 4. Code Generation │ │ SparkPlan → Java Bytecode │ │ (Whole-Stage CodeGen, Janino 컴파일) │ └───────────────────┬──────────────────────────────┘ ↓ RDD 실행Analysis (분석 단계)
SQL 파서 또는 DataFrame API로 생성된 Unresolved Logical Plan을 Analyzed Logical Plan으로 변환합니다.
df = spark.sql("SELECT name, age FROM employees WHERE dept = 'Engineering'") # Unresolved Logical Plan (분석 전) — 모든 참조가 미해결 상태 # Project [unresolvedAttr(name), unresolvedAttr(age)] # └── Filter unresolvedAttr(dept) = 'Engineering' # └── UnresolvedRelation employees # Analyzed Logical Plan (분석 후) — Catalog에서 해석 완료 # Project [name#10, age#11] # └── Filter (dept#12 = 'Engineering') # └── Relation employees [name#10, age#11, dept#12, salary#13] # ^^^^ 고유 ID 부여됨Logical Optimization (논리 최적화 단계)
분석이 완료된 논리 계획에 규칙 기반 최적화를 적용하여 Optimized Logical Plan을 생성합니다.
규칙 설명 Constant Folding 1+2→3, 컴파일 시점에 상수 계산Predicate Pushdown 필터를 데이터 소스 방향으로 이동 Projection Pruning 필요 없는 컬럼 제거 Combine Filters 인접한 필터 조건 병합 Null Propagation Null 값 처리 최적화 Boolean Simplification 불린 연산 단순화 OptimizeIn 단일 원소 IN 리스트를 등호 비교로 변환 df = spark.read.parquet("/data/employees") \ .filter("age > 20").filter("age > 30") \ .select("name", "age", "salary") df.explain(True) # ── Optimized Logical Plan ── # Project [name#10, age#11] ← salary 제거 (Projection Pruning) # └── Filter (age#11 > 30) ← 두 Filter 병합 + 약한 조건 제거 # └── Relation employeesPhysical Planning (물리 계획 단계)
최적화된 논리 계획을 Spark 실행 엔진이 수행할 SparkPlan으로 변환합니다. SparkPlanner가 10가지 전략으로 물리 연산자를 매핑하고, CBO로 최적 계획을 선택합니다.
orders = spark.read.parquet("/data/orders") customers = spark.read.parquet("/data/customers") # 소규모 (10MB 이하) orders.join(customers, "customer_id").filter("order_date > '2024-01-01'").explain() # ── Physical Plan ── # *(2) BroadcastHashJoin [customer_id#2], [customer_id#21] # :- *(2) Filter (order_date#4 > 2024-01-01) # : +- *(2) FileScan parquet orders # +- BroadcastExchange HashedRelationBroadcastMode ← 소규모 테이블 브로드캐스트 # +- *(1) FileScan parquet customersCode Generation (코드 생성 단계)
Whole-Stage Code Generation: 여러 물리 연산자를 단일 Java 함수로 묶어 컴파일합니다.
*(1)프리픽스가 단일 코드젠 스테이지를 의미합니다. Janino 컴파일러가 런타임에 바이트코드를 생성합니다.df = spark.range(1_000_000).selectExpr("id * 2 + 1 as value").filter("value > 100") df.explain() # *(1) Filter (((id#0L * 2) + 1) > 100) ← 두 연산자가 # +- *(1) Range (0, 1000000, step=1) ← 단일 Java 함수로 컴파일됨 # # for (long id = 0; id < 1000000; id++) { # long value = id * 2 + 1; # if (value > 100) emit(value); ← 인라인 처리, 함수 호출 오버헤드 없음 # }Code Generation 성능 비교 (출처: Databricks):
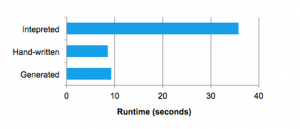
Code Generation 성능 비교 — Volcano 모델 vs Whole-Stage CodeGen
3. I/O 최적화 전략
I/O 최적화는 카탈리스트가 제공하는 가장 강력한 성능 개선 수단입니다. 3개 계층이 함께 동작하면 쿼리가 실제로 읽는 데이터를 전체의 1% 미만으로 줄일 수 있습니다.
3계층 I/O 최적화: ┌─────────────────────────────────────────────────────────┐ │ Layer 1: Partition Pruning │ │ 디렉토리 레벨 — 관련 없는 파티션 폴더 자체를 스킵 │ │ 예) dt=2025-01-15/ 만 접근, 나머지 364개 폴더 무시 │ ├─────────────────────────────────────────────────────────┤ │ Layer 2: Data Skipping (File-level) │ │ 파일 레벨 — min/max 통계로 전체 파일 스킵 │ │ 예) file.parquet min=100, max=200 → value=50 조건 스킵 │ ├─────────────────────────────────────────────────────────┤ │ Layer 3: Predicate Pushdown + Column Pruning │ │ 행·컬럼 레벨 — 조건 행만 읽고, 필요 컬럼만 읽음 │ │ 예) PushedFilters, ReadSchema 컬럼 제한 │ └─────────────────────────────────────────────────────────┘3.1 Predicate Pushdown (술어 푸시다운)
필터 조건을 데이터 소스 레벨로 이동시켜 조건을 만족하지 않는 행은 처음부터 읽지 않습니다.
푸시다운 없음: 푸시다운 적용: ┌───────────────┐ ┌───────────────┐ │ Spark Filter │ ← 1억 건 처리 │ Spark │ ← 10만 건만 처리 └───────┬───────┘ └───────┬───────┘ │ 1억 건 전송 │ 10만 건만 전송 ┌───────┴───────┐ ┌───────┴───────┐ │ Parquet │ → 전체 스캔 │ Parquet │ → 조건 행만 반환 └───────────────┘ └───────────────┘df = spark.read.parquet("/data/sales") \ .filter("region = 'KR' AND amount > 10000") \ .select("product_id", "amount") df.explain() # *(1) FileScan parquet [product_id#5, amount#7, region#9] # PushedFilters: [IsNotNull(region), EqualTo(region,KR), # IsNotNull(amount), GreaterThan(amount,10000)] # ReadSchema: struct<product_id:string, amount:long>지원 포맷: Parquet, ORC, JDBC, Delta Lake 등 FileScan 기반 소스
푸시다운이 작동하지 않는 경우:
- UDF 사용 시 — 옵티마이저가 내부 로직을 분석할 수 없음
- 복잡한 Window 함수 — 일부 제한 존재
# ❌ UDF → PushedFilters: [] (전체 로드 후 처리) df.filter(my_udf(df.age)).explain() # ✅ 내장 함수 → PushedFilters: [GreaterThan(age,60)] df.filter(df.age > 60).explain()3.2 Column Pruning (컬럼 제거)
쿼리 결과에 필요한 컬럼만 읽고 나머지는 I/O 단계에서 완전히 제외합니다.
# 원본 테이블: employees(id, name, age, salary, dept, phone, address, join_date) df = spark.read.parquet("/data/employees").select("id", "name") df.explain() # *(1) FileScan parquet [id#1, name#2] # ReadSchema: struct<id:int, name:string> # → 나머지 6개 컬럼은 디스크에서 아예 읽지 않음 (I/O 75% 절감)Parquet·ORC 같은 컬럼 단위 저장 포맷과 결합 시 I/O 절감 효과가 극대화됩니다.
3.3 Partition Pruning (파티션 프루닝)
파티션 디렉토리 자체를 접근하지 않는 기법입니다. Predicate Pushdown이 파일 내부의 행을 필터링한다면, 파티션 프루닝은 디렉토리 자체를 건너뜁니다.
Static Partition Pruning — 쿼리 컴파일 시점에 파티션 결정:
# 파티션 구조: /data/sales/dt=2025-01-01/ ~ dt=2025-12-31/ (365개) df = spark.read.parquet("/data/sales") df.filter("dt = '2025-01-15'").explain() # *(1) FileScan parquet [amount#1, dt#2] # PartitionFilters: [isnotnull(dt#2), (dt#2 = 2025-01-15)] ← 프루닝 적용 # → dt=2025-01-15/ 하나만 접근 (364개 파티션 스킵)Dynamic Partition Pruning (DPP, Spark 3.0+) — 조인 시 런타임에 파티션 결정:
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true") fact = spark.read.parquet("/data/sales") # 파티션: dt dim = spark.read.parquet("/data/promotions") # 소규모 차원 테이블 result = fact.join(dim, "campaign_id").filter("dim.region = 'KR'") result.explain() # FileScan parquet sales # PartitionFilters: [dynamicpruningexpression(dt#2 IN subquery#1)] ← DPP # → dim의 KR 캠페인 날짜에 해당하는 파티션만 런타임에 스캔3.4 Data Skipping (데이터 스키핑)
Parquet 파일은 각 Row Group(기본 128MB)마다 컬럼별 min/max 통계를 저장합니다. Spark은 이 통계를 읽어 조건을 만족할 수 없는 Row Group 전체를 스킵합니다.
Parquet 파일 내부: ┌──────────────────────────────────────┐ │ Row Group 1 │ age: min=18, max=35 │ ← age > 80 → 스킵 (max=35 < 80) │ Row Group 2 │ age: min=36, max=60 │ ← age > 80 → 스킵 (max=60 < 80) │ Row Group 3 │ age: min=61, max=85 │ ← age > 80 → 읽음 (max=85 >= 80) └──────────────────────────────────────┘ → 3개 중 1개만 스캔 (67% I/O 절감)df = spark.read.parquet("/data/employees") df.filter("age > 80").explain() # *(1) FileScan parquet [age#1, name#2] # PushedFilters: [IsNotNull(age), GreaterThan(age,80)] # RowGroups: 3 out of 10 read ← 10개 Row Group 중 3개만 읽음 # 설정: spark.sql.parquet.filterPushdown = true (기본값)Delta Lake Data Skipping + Z-Order:
# Delta Lake: 트랜잭션 로그(_delta_log/)에 파일별 min/max 통계 자동 저장 (기본 32컬럼) # Z-Order로 같은 값의 데이터를 같은 파일에 클러스터링 → min/max 범위 최소화 spark.sql(""" OPTIMIZE delta.`/data/events` ZORDER BY (user_id, event_date) """) # → user_id 기반 조회 시 대부분의 파일 min/max 범위 밖 → 스킵 가능
4. 조인 & 실행 최적화
4.1 Broadcast Join (브로드캐스트 조인)
한쪽 테이블이 충분히 작을 경우, 셔플 없이 작은 테이블을 모든 노드에 복사(broadcast)하여 조인합니다.
from pyspark.sql.functions import broadcast orders = spark.read.parquet("/data/orders") # 10억 건 country_codes = spark.read.parquet("/data/codes") # 200건 (소규모) # 자동 감지 (10MB 이하 → 자동 브로드캐스트) spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10m") # 명시적 강제 적용 orders.join(broadcast(country_codes), "country_code").explain() # BroadcastHashJoin vs SortMergeJoin # ┌──────────────────────┬──────────────────────┐ # │ BroadcastHashJoin │ SortMergeJoin │ # ├──────────────────────┼──────────────────────┤ # │ 네트워크 셔플 없음 │ 전체 데이터 셔플 │ # │ 소규모 테이블 필요 │ 테이블 크기 무관 │ # │ 훨씬 빠름 │ 대규모 조인에 안정적 │ # └──────────────────────┴──────────────────────┘4.2 Join Reordering & CBO (조인 재정렬 & 비용 기반 최적화)
CBO는 데이터 통계(행 수, 컬럼 분포, NDV 등)를 바탕으로 여러 실행 계획 중 비용이 가장 낮은 계획을 선택합니다. 조인 재정렬에 주로 활용됩니다.
spark.conf.set("spark.sql.cbo.enabled", "true") # 통계 수집 spark.sql("ANALYZE TABLE orders COMPUTE STATISTICS FOR ALL COLUMNS") spark.sql("ANALYZE TABLE products COMPUTE STATISTICS FOR ALL COLUMNS") # 수집된 통계 확인 spark.sql("DESCRIBE EXTENDED my_table").show(truncate=False) # Statistics: 1234567890 bytes, 10000000 rows # col_stats: age → min:18, max:80, ndv:62 | region → ndv:8 # CBO 비활성화: 작성 순서 그대로 orders.join(customers, "cid").join(products, "pid").explain() # SortMergeJoin orders × customers → 결과 × products (비효율) # CBO 활성화: 통계 기반 최적 순서 orders.join(customers, "cid").join(products, "pid").explain() # BroadcastHashJoin products(소규모 먼저) → 결과 × orders ← 재정렬4.3 Adaptive Query Execution (AQE, Spark 3.0+)
런타임에 수집한 실측 통계를 기반으로 실행 중 계획을 동적으로 재최적화합니다.
기능 설명 파티션 동적 조정 초기 200 파티션 → 실제 데이터 기반 15개로 병합 조인 전략 변경 Sort-Merge → Broadcast (런타임 크기 확인 후) 스큐 조인 처리 특정 키에 데이터가 몰려도 자동 파티션 분할 spark.conf.set("spark.sql.adaptive.enabled", "true") # Spark 3.2+에서 기본 true spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true") spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true") df = spark.read.parquet("/data/events").groupBy("event_type").agg({"user_id": "count"}) df.explain() # AdaptiveSparkPlan isFinalPlan=false ← AQE 활성화 표시 # +- HashAggregate # +- Exchange hashpartitioning(event_type, 200) ← 초기 200 파티션 # # 실행 후: 실제 데이터 있는 15개로 자동 병합 (빈 태스크 185개 제거)
5. 실무 주의사항: 파티션 키와 함수
5.1 파티션 키에 함수를 감싸면 안 되는 이유 (오픈소스 Spark)
파티션 키 컬럼을 함수로 감싸면 파티션 프루닝이 완전히 무력화됩니다.
옵티마이저가 파티션 프루닝을 적용하려면 컴파일 시점에 어느 파티션 디렉토리를 읽을지 결정해야 합니다.
to_date(dt) = '2025-01-01'이라고 쓰면, 옵티마이저 입장에서는 dt의 모든 값을 실제로 읽어서 함수를 적용해 봐야 결과가 맞는지 알 수 있습니다. 따라서 프루닝을 포기하고 전체 파티션을 스캔합니다.파티션 디렉토리: /data/logs/dt=2025-01-01/ ~ dt=2025-12-31/ (365개) [BAD] to_date(dt) = '2025-01-01' → 옵티마이저: 어느 dt= 폴더를 써야 하는지 알 수 없음 → 전체 365개 파티션 스캔 후 함수 적용 [GOOD] dt = '2025-01-01' → 옵티마이저: dt=2025-01-01 폴더만 직접 접근 → 1개 파티션만 스캔❌ 프루닝 무력화 패턴 vs ✅ 올바른 패턴:
-- ❌ 함수 적용 → PartitionFilters: [] (전체 스캔) WHERE to_date(dt) = '2025-01-01' WHERE datetime(dt) >= '2025-01-01 00:00:00' WHERE date_format(dt, 'yyyy-MM') = '2025-01' WHERE YEAR(dt) = 2025 AND MONTH(dt) = 1 -- ✅ 직접 비교 → PartitionFilters 적용 (스킵) WHERE dt = '2025-01-01' WHERE dt >= '2025-01-01' AND dt < '2025-01-02' WHERE dt BETWEEN '2025-01-01' AND '2025-01-31'EXPLAIN으로 차이 확인:
df = spark.read.parquet("/data/logs") # dt 컬럼으로 파티션됨 # ❌ 잘못된 패턴 from pyspark.sql.functions import to_date df.filter(to_date(df.dt) == '2025-01-01').explain() # FileScan parquet # PartitionFilters: [] ← 비어 있음! 전체 파티션 스캔 # ✅ 올바른 패턴 df.filter("dt = '2025-01-01'").explain() # FileScan parquet # PartitionFilters: [isnotnull(dt#1), (dt#1 = 2025-01-01)] ← 프루닝 적용Z-Order 클러스터링에서도 동일하게 적용됩니다:
-- ❌ 함수 적용 → min/max 통계 비교 불가 → 데이터 스키핑 안 됨 WHERE CAST(user_id AS STRING) = '12345' -- ✅ 직접 비교 → min/max 통계 활용 → 대부분 파일 스킵 WHERE user_id = 123455.2 Databricks Delta Lake의 자동 해법: Generated Columns
위의 문제를 Databricks Delta Lake는 Generated Columns(생성 컬럼)으로 자동 해결합니다.
Generated Column은 다른 컬럼의 함수로 자동 계산되는 특수 컬럼입니다. 파티션 컬럼을 Generated Column으로 정의하면, Delta Lake가 기본 컬럼으로 필터링해도 파티션 필터를 자동 생성합니다.
동작 원리:
[테이블 스키마] event_time TIMESTAMP ← 실제 데이터 컬럼 event_date DATE (Generated) ← CAST(event_time AS DATE) 로 자동 계산 [쿼리] WHERE event_time >= '2025-01-01' [Delta Lake 내부 처리] event_time과 event_date의 관계를 알고 있음 → event_date = '2025-01-01' 파티션 필터 자동 추가 → 해당 파티션만 스캔생성 컬럼으로 테이블 정의:
CREATE TABLE events ( event_id BIGINT, event_time TIMESTAMP, user_id BIGINT, -- Generated Column: event_time으로부터 자동 계산, 직접 삽입 불필요 event_date DATE GENERATED ALWAYS AS (CAST(event_time AS DATE)) ) USING DELTA PARTITIONED BY (event_date); -- 쓰기 시: event_date를 직접 지정할 필요 없음 (Delta가 자동 계산) INSERT INTO events (event_id, event_time, user_id) VALUES (1, '2025-01-15 14:30:00', 12345); -- → event_date = '2025-01-15' 자동 저장기본 컬럼으로 필터링해도 파티션 프루닝 자동 적용:
-- event_date 조건 없이 event_time으로만 필터링 SELECT * FROM events WHERE event_time >= '2025-01-01' AND event_time < '2025-01-02'; -- Delta Lake 내부 처리: -- event_time >= '2025-01-01' → event_date = '2025-01-01' 자동 추가 -- → EXPLAIN 출력: PartitionFilters: [(event_date = 2025-01-01)] -- → event_date=2025-01-01/ 파티션 하나만 스캔지원 표현식 목록:
표현식 컬럼 타입 설명 CAST(col AS DATE)TIMESTAMP 타임스탬프 → 날짜 변환 YEAR(col)TIMESTAMP 연도 추출 YEAR(col)•MONTH(col)TIMESTAMP 연·월 파티션 YEAR(col)•MONTH(col)•DAY(col)TIMESTAMP 연·월·일 파티션 YEAR(col)•MONTH(col)•DAY(col)•HOUR(col)TIMESTAMP 시간 단위 파티션 DATE_FORMAT(col, 'yyyy-MM')TIMESTAMP 월별 파티션 SUBSTRING(col, pos, len)STRING 문자열 부분 파티션 Photon 요구사항:
- Databricks Runtime 10.4 LTS 이하 → Photon 필수
- Databricks Runtime 11.3 LTS 이상 → Photon 불필요 (자동 적용)
오픈소스 Spark vs Databricks 비교:
항목 오픈소스 Spark Databricks Delta Lake to_date(dt) = '2025-01-01'PartitionFilters: [] (전체 스캔) Generated Column 설정 시 자동 프루닝 YEAR(dt) = 2025프루닝 불가 Generated Column 설정 시 자동 프루닝 dt = '2025-01-01'정상 프루닝 정상 프루닝 설정 필요 여부 없음 (직접 비교만 동작) 테이블 생성 시 Generated Column 정의 필요 5.3 다중 파티션 키 (ym + dt) 와 프루닝 범위
실무에서는 파티션을
ym(연월)+dt(날짜)두 계층으로 구성하는 경우가 많습니다. 이 때WHERE dt = '2025-01-15'조건만 사용하면 상위 파티션ym까지 프루닝되는지는 오픈소스 Spark와 Databricks 간에 동작이 다릅니다.파일시스템 계층 구조 (ym + dt 2단계 파티션):
/data/logs/ ym=2025-01/ dt=2025-01-01/ ← part-00000.parquet dt=2025-01-15/ ← part-00000.parquet (찾고자 하는 파티션) dt=2025-01-31/ ym=2025-02/ dt=2025-02-01/ ... ym=2025-12/ ...오픈소스 Spark — dt 조건만으로는 ym 프루닝 안 됨:
오픈소스 Spark는
ym과dt사이의 논리적 관계를 모릅니다.dt = '2025-01-15'라고 써도 옵티마이저는 해당 dt가 어느ym=폴더 아래 있는지 추론할 수 없습니다. 결국 모든ym=*/디렉토리를 열어 안에 있는dt=서브파티션을 하나씩 확인합니다.df = spark.read.parquet("/data/logs") # PARTITIONED BY (ym, dt) # ❌ dt만 명시 → ym 전체 스캔 df.filter("dt = '2025-01-15'").explain() # FileScan parquet # PartitionFilters: [isnotnull(dt#2), (dt#2 = 2025-01-15)] # ← dt 만 프루닝. ym은 비어있어 12개 ym 폴더 모두 진입 # → 실제로는 ym=2025-01/dt=2025-01-15/ 1개만 필요하지만 # ym=2025-02/ ~ ym=2025-12/ 도 모두 열어서 dt 확인 후 버림 # ✅ ym 까지 명시 → 두 레벨 모두 프루닝 df.filter("ym = '2025-01' AND dt = '2025-01-15'").explain() # PartitionFilters: [(ym#1 = 2025-01), (dt#2 = 2025-01-15)] ← 두 레벨 동시 적용Databricks Delta Lake — Generated Column으로 ym 자동 프루닝:
ym을dt의 Generated Column으로 정의하면 Delta Lake가 두 컬럼의 관계를 인식하여,dt조건만 있어도 상위 파티션ym을 자동으로 프루닝합니다.CREATE TABLE logs ( log_id BIGINT, dt DATE, -- ym 은 dt 로부터 자동 계산되는 Generated Column ym STRING GENERATED ALWAYS AS (DATE_FORMAT(dt, 'yyyy-MM')), message STRING ) USING DELTA PARTITIONED BY (ym, dt); -- dt 조건만 사용 → Delta Lake 가 ym 파티션 필터 자동 추가 SELECT * FROM logs WHERE dt = '2025-01-15'; -- Delta Lake 내부: -- dt = '2025-01-15' → ym = '2025-01' 자동 추론 -- PartitionFilters: [(ym = '2025-01'), (dt = '2025-01-15')] -- → ym=2025-01/dt=2025-01-15/ 1개 파티션만 스캔오픈소스 Spark vs Databricks — 다중 파티션 키 프루닝 비교:
필터 조건 오픈소스 Spark Databricks Delta Lake WHERE dt = '2025-01-15'dt만 프루닝, ym 전체 스캔 Generated Column 정의 시 ym도 자동 프루닝 WHERE ym='2025-01' AND dt='2025-01-15'두 레벨 모두 프루닝 두 레벨 모두 프루닝 상위 파티션 자동 추론 불가 (독립적으로 처리) dt → ym 관계 인식 (Generated Column) 설정 필요 여부 없음 (명시 조건만 동작) 테이블 생성 시 Generated Column 정의 필요 핵심: 오픈소스 Spark에서 계층형 다중 파티션을 사용할 때, 상위 파티션(ym)을 프루닝하려면 WHERE 절에 반드시 명시해야 합니다. Databricks Delta Lake는 Generated Column 정의만으로 이 제약을 자동으로 해결합니다.
6. 요약
카탈리스트 옵티마이저는 Apache Spark의 쿼리 최적화 핵심 엔진으로, 사용자의 쿼리를 최적의 실행 계획으로 변환합니다.
4단계 파이프라인:
단계 역할 방식 Analysis 이름·타입 해석 규칙 기반 Logical Optimization 논리 계획 단순화 규칙 기반 (25배치, 69규칙) Physical Planning 물리 연산자 매핑 규칙 + 비용 기반 Code Generation Java 바이트코드 컴파일 Whole-Stage CodeGen 핵심 최적화 기법:
기법 계층 설명 Predicate Pushdown 행 레벨 조건 행만 읽음 Column Pruning 컬럼 레벨 필요 컬럼만 읽음 Partition Pruning 디렉토리 레벨 관련 파티션 폴더만 접근 Data Skipping Row Group 레벨 min/max 통계로 블록 스킵 Broadcast Join 조인 전략 소규모 테이블 셔플 없이 복사 CBO 계획 선택 통계 기반 최소 비용 계획 선택 AQE 런타임 재최적화 실측 기반 동적 조정 (Spark 3.0+) 실무 핵심 주의사항:
파티션/클러스터링 키를
to_date(),datetime(),YEAR()등 함수로 감싸면 Partition Pruning과 Data Skipping이 완전히 무력화됩니다. 직접 리터럴 비교를 사용해야 합니다.단, Databricks Delta Lake는 테이블 생성 시 Generated Columns를 정의하면, 기본 컬럼에 함수를 적용한 필터에서도 파티션 프루닝을 자동으로 처리합니다 (DBR 11.3 LTS 이상, Photon 불필요).
7. 레퍼런스
- Deep Dive into Spark SQL's Catalyst Optimizer — Databricks Blog (2015)
- Apache Spark SQL Performance Tuning — Official Docs
- Delta Lake Generated Columns — Databricks Official Docs
- Delta Lake OSS — Optimizations
- Partition Pruning in Apache Spark — Unravel Data
- Static and Dynamic Partition Pruning in Apache Spark — WaitingForCode
- Spark Catalyst Optimizer — SparkCodeHub
- Whole-Stage Code Generation — SparkPlayground
- Adaptive Query Execution — Databricks Blog