-
노드 생성, 동작 원리 및 shard란?LogSystem 2015. 11. 14. 21:17
1) 노드의 생성 및 동작 원리
사용자가 하나의 머신에서 Elasicsearch를 시작하게 되면, 하나의 Elasticsearch 노드가 생성되며, 이 노드는 동일한 네트워크 상에서 같은 클러스터명을 같는 클러스터가 존재하는 지를 찾게 됩니다. 만약, 연결(join)될 수 있는 클러스터가 없다면 이 노드는 스스로 클러스터를 생성하게 되고, 만약 클러스터가 존재한다면 해당 클러스터에 연결됩니다.
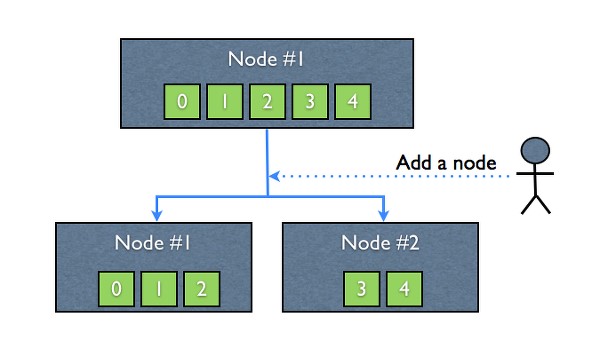
새로운 클러스터가 생성되었다면, 노드에는 아직 어떠한 인덱스도 존재하지 않는 상태이며, 새로운 인덱스를 생성할 때 인덱스를 몇 개의 shard로 나누어 저장할 것인지를 정의할 수 있습니다. Shard의 개수를 따로 지정하지 않는다면, Elasticsearch의 기본 shard 개수인 5개로 데이터가 나누어져 저장됩니다. 만약, 노드가 기존에 존재하던 클러스터에 연결되고 해당 클러스터에 이미 인덱스가 존재한다면 해당 인덱스 shard들은 추가된 노드에 균일하게 재분산 됩니다.(그림 1)

(그림1)
2) shard란?
Elasticsearch를 비롯한 많은 수의 분산 데이터베이스(분산 검색엔진)에서 shard란 일종의 파티션과 같은 의미이며, 데이터를 저장할 때 나누어진 하나의 조각에 대한 단위입니다. 여기에서 주의할 점은 각각의 shard는 데이터에 대한 복사본이 아니라, 데이터 그 자체라는 점입니다. shard가 노드에 저장되어 있는 상태에서 위 (그림1)과 같이 하나의 노드가 추가 된다면, 기존에 존재하던 shards는 각 노드에 균일하게 재분산 됩니다. 이렇게 가장 먼저 1copy씩 존재하는 데이터 shard를 primary shard라고 합니다.
Elasticsearch는 분산 데이터베이스(분산 검색엔진)이기 때문에, 이렇게 데이터를 나누어 저장하는 방식으로 대용량 데이터에 대한 분산처리를 가능하게 합니다. Primary shard는 각 인덱스 별로 최소 1개 이상 존재해야만 합니다. Shard가 많아지면 그만큼 데이터양의 증가에 대한 Elasticsearch 노드의 확장으로 대응이 가능하다는 장점이 있습니다. 하지만, shard 그 자체도 일종의 비용이라고 할 수 있기 때문에 데이터양의 증가 예측치를 이용하여 적절한 수의 shard를 결정하는 것이 중요합니다.
3) replica란?
Replica는 한 마디로 정의하자면 또 다른 형태의 shard라고 할 수 있습니다. Elasticsearch에서 replica의 기본값은 1입니다. 이 때, replica의 값이 1이라는 것은 primary shard가 1개라는 것을 의미하지 않고, primary shard와 동일한 복제본이 1개 있다는 것을 의미합니다. 즉, replica의 개수는 primary shard를 제외한 복제본의 개수 입니다. Replica가 필요한 이유는 크게 두 가지인데, 그 중 첫 번째는 ‘검색성능(search performance)‘이고, 두 번째는 ‘장애복구(fail-over)‘입니다.
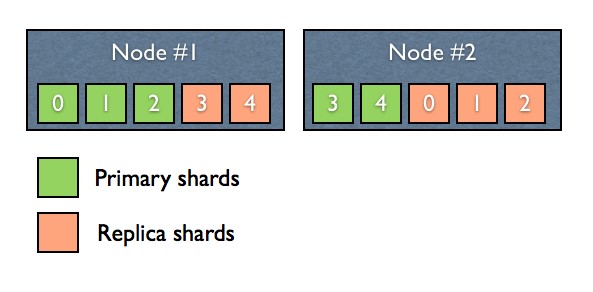
Replica shard는 동일한 데이터를 갖고 있는 primary shard와 같은 elasticsearch 노드 상에 존재할 수 없습니다.

(그림 2)
그림 2) 와 같이 중복되지 않게 각 노드에 존재하게 됩니다. 이러한 이유는 하나의 노드에 문제가 발생해도 나머지 노드에 모든 데이터 shard들이 존재하기 때문에 정상적인 서비스가 가능하며, 문제가 없는 노드에 있던 replica shard가 자동적으로 primary shard가 됩니다.
즉 n개의 노드에서 문제가 발생했을 때, 최소 n+1개의 노드가 동일한 클러스터 안에 존재해야하며, replica의 최소 갯수는 n개, 최대 갯수는 전체 노드 수 - 1개여야 합니다.